De-identified data is only safe when you pick the right HIPAA path, remove both direct and indirect identifiers, and test re-identification risk before sharing it.
If I had to boil this article down, here’s the answer: use Safe Harbor when you can remove all 18 HIPAA identifiers without hurting the data too much, and use Expert Determination when you need to keep more detail. After that, I would check every data type - structured fields, notes, images, PDFs, and metadata - because hidden PHI can stay behind even after a clean field-level pass.
A few facts make the risk clear:
- More than 50% of U.S. residents can be singled out by date of birth, sex, and 5-digit ZIP Code
- One cited finding puts re-identification risk at 87% when ZIP code, gender, and date of birth are combined
- Under HIPAA, de-identified data falls outside the Privacy Rule only when the de-identification standard is met
Here’s the short checklist I’d use:
- Choose the HIPAA method: Safe Harbor or Expert Determination
- Strip direct identifiers: names, IDs, contact data, IP addresses, biometrics, and more
- Reduce linkage risk: generalize dates, age, and ZIP codes; suppress risky records when needed
- Review hidden PHI: free text, DICOM headers, burned-in image text, PDF comments, layers, and metadata
- Document every step: method used, fields changed, reviewers, thresholds, and review dates
- Retest before reuse or sharing: especially after refreshes, vendor transfers, external joins, or AI reuse
- Tie it to approvals: privacy, security, compliance, and data-sharing review should all be part of the same process
| HIPAA path | Best when | Main tradeoff |
|---|---|---|
| Safe Harbor | You want a clear rules-based route | Less data detail |
| Expert Determination | You need more usable data | More analysis and documentation |
Bottom line: I’d treat de-identification as a repeatable review process, not a one-time scrub. That keeps patient privacy in view while giving teams data they can still use.
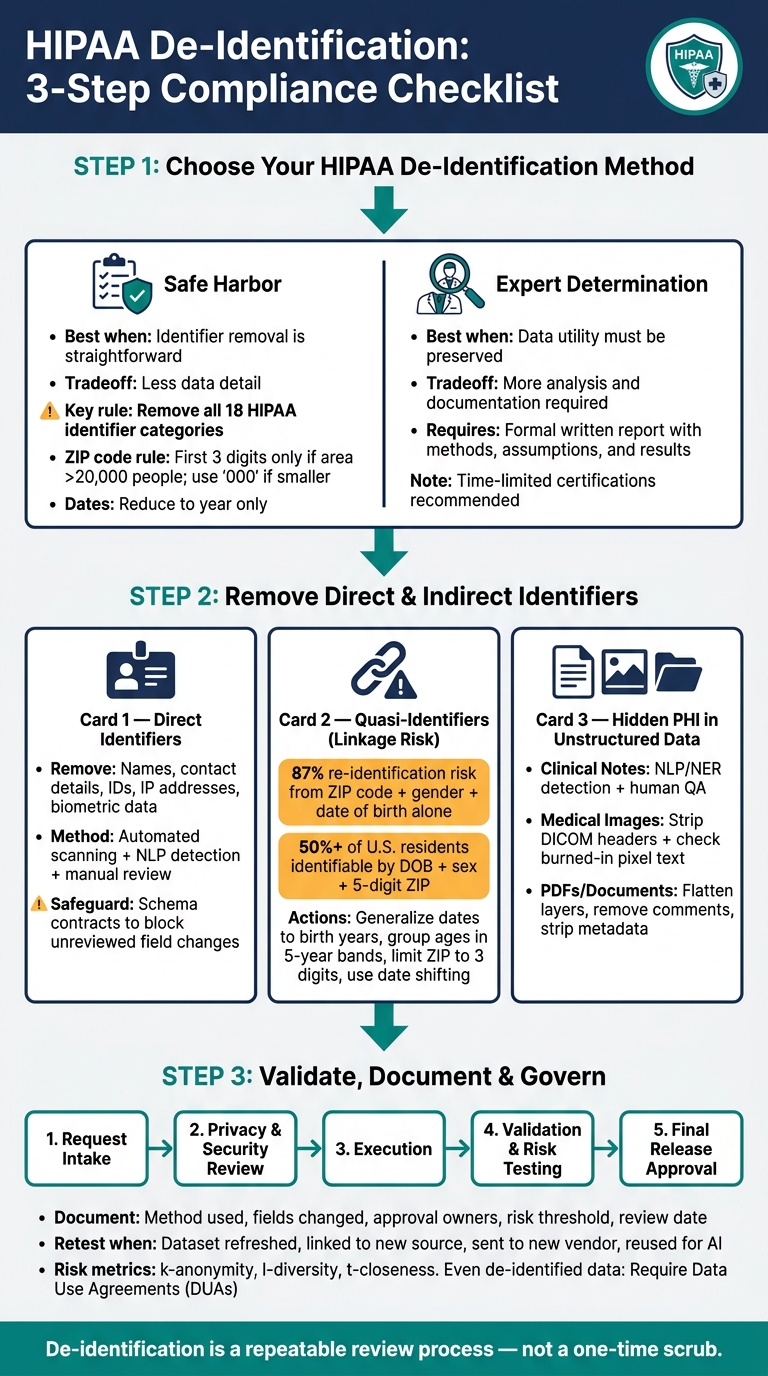
HIPAA De-Identification: 3-Step Compliance Checklist
De-Identifying Healthcare Data for Research
sbb-itb-535baee
Checklist item 1: Choose the right HIPAA de-identification method
Pick the method based on how the data will be used. Start with the option that lines up with the level of detail you need to keep.
Use Safe Harbor when identifier removal is straightforward
Safe Harbor follows a set checklist. You remove all 18 identifier categories and confirm that your organization has no "actual knowledge" that the remaining data could still identify someone.[1][6]
This approach works well for large structured datasets. The tradeoff is simple: the data becomes less useful for analysis. Safe Harbor requires turning specific dates into the year only and shortening ZIP codes to the first three digits, but only when that geographic area has more than 20,000 people.[1][5] If the population is smaller, the ZIP code has to be replaced with 000.
There’s another catch. Safe Harbor doesn’t deal with free-text fields, scanned documents, or medical images on its own. Identifiers tucked inside clinical notes or burned into radiology images can slip past a sweep of structured fields, so unstructured content needs its own review.[6][5]
Use Expert Determination when data utility must be preserved
Expert Determination works differently. A qualified expert with statistical or scientific expertise uses accepted methods to show that the risk of re-identification is "very small."[1] That gives you more room to keep details that Safe Harbor would remove.
This method also comes with more paperwork. It requires a formal written report that lays out the expert’s methods, assumptions, and results.[1][4] And because outside data sources and reidentification methods change over time, experts often issue time-limited certifications that should be reviewed again when conditions shift.[1]
Match the method to the intended data use case
Use Safe Harbor when you want a plain, auditable path and can live with less granular data. Use Expert Determination when the data needs to keep more detail for analysis.
Once you’ve chosen the method, remove both direct and indirect identifiers across every data type. Then move to technical controls so identifiers are stripped from both structured and unstructured data.
Checklist item 2: Apply technical controls to remove direct and indirect identifiers
Once you've picked a de-identification method, the next step is simple in theory and messy in practice: remove identifiers from every system, export, and file type. The aim is to strip out what points to a patient, while keeping the data usable for its job.
Remove direct identifiers across all data fields
Start by removing all HIPAA identifiers, including names, contact details, IDs, IP addresses, and biometric data.[5][2]
This shouldn't be a one-pass check. It needs a few layers:
- Automated scanning for structured fields
- NLP-assisted detection for free text
- Manual review of data samples[5][7]
One safeguard that's worth putting in place is schema contracts. These can block files that contain new fields or odd data types. That matters because an unreviewed schema change can slip PHI back into a dataset that looked clean before.[7]
Reduce quasi-identifiers and linkage risk
Direct identifiers are only one part of the issue. Quasi-identifiers can look harmless by themselves, but when combined, they can point back to a person. One well-known finding shows that just three attributes - ZIP code, gender, and date of birth - can create an 87% re-identification risk for people in the United States.[8]
The usual fix is generalization and suppression. In plain English, that means making some fields less exact or removing them when they create too much risk. For example, convert full birth dates to birth years, group ages into five-year bands, and limit ZIP codes to the first three digits when that area has more than 20,000 people. If it doesn't, use "000." Date shifting can also help preserve time intervals without exposing the actual dates.[7][3]
Some records need extra care. Rare diagnoses or unusual encounter patterns can make one patient stand out, even inside a large dataset. In those cases, suppressing the record or the risky fields may be the safer move.[5][6]
Check unstructured data, images, and metadata for hidden PHI
Hidden PHI in notes, images, or metadata can undo an otherwise clean export. This is where things get tricky. Clinical notes, images, transcripts, and PDFs often carry identifiers in places a basic field scan will never touch.
For clinical notes and transcripts, NLP and Named Entity Recognition (NER) tools can help find names, locations, and rare terms. But they still need human QA, because automated tools miss things.[5][7]
Medical devices and images need two checks. First, strip PHI from DICOM headers. Then review the image itself for burned-in text, such as patient names or IDs embedded in the pixels instead of the metadata.[5][3]
PDFs and exported documents have their own traps. Document properties, tracked changes, comments, and embedded layers can all hold PHI that survives a visual review. Flatten layers, remove comments, and run a text search on the final output to make sure the redaction can't be reversed.[6]
| Data Source | What to Check | Recommended Action |
|---|---|---|
| Clinical Notes | Names, dates, rare terms in free-text | NLP/NER detection + human QA; replace with standardized tokens |
| Medical Images | DICOM headers, burned-in pixel text | Strip DICOM tags; crop or blur identifiers in the image itself |
| PDFs / Documents | Metadata, layers, tracked changes, comments | Flatten layers; remove comments and document properties |
After removal is done, validate residual risk and document the result. This documentation is a critical component of managing broader enterprise risk across the organization.
Checklist item 3: Validate risk, governance, and documentation before data is used or shared
Once the technical removal work is done, the job isn't over. You still need to check the remaining risk before anything gets released. If a de-identified dataset is headed into analytics, an AI model, or a vendor environment, use a repeatable review process, not a one-off check, to make sure the data is ready to share.
Document methods, assumptions, and approval steps
Every de-identification decision needs a clear record. Write down the method used, the fields that were changed, the approval owners, the risk threshold, and the review date.
For Expert Determination, include the expert's qualifications, the statistical methods used, the risk threshold, and a signed attestation that re-identification risk is very small. [1][5][9] If a re-identification code is used for future linkage, document that the code is not derived from the individual's information and that the mechanism for re-identification is stored separately and securely. [1]
Privacy, compliance, and security teams should each have a documented role in the review. [5][9]
Test for re-identification risk on a regular basis
Validation should be part of release approval, not some later cleanup task. Risk changes over time. New tools show up, outside datasets get bigger, and data that looked low-risk a year ago may not look so safe now.
"Experts have recognized that technology, social conditions, and the availability of information changes over time. Consequently, certain de-identification practitioners use the approach of time-limited certifications." - HHS.gov [1]
Retesting should happen when something changes, such as:
- a dataset is refreshed or expanded
- it is linked with a new external source
- it is sent to a new vendor
- it is reused for a new AI model [5][10]
During each review, check for uniqueness, rare diagnoses, unusual encounter patterns, and unauthorized join keys that could link the data to outside sources. Statistical measures like k-anonymity, l-diversity, and t-closeness give you a structured way to measure what risk remains. [5][10]
Connect de-identification to enterprise risk workflows
De-identification governance shouldn't sit in a spreadsheet owned by one privacy analyst. It needs to be built into intake, third-party vendor risk management, and data-sharing approval workflows.
A structured intake-to-release pipeline - covering request intake, privacy and security review, execution, validation, and final release approval - gives each dataset the same path and a clear owner at every stage. [11] De-identification review should also line up with third-party and data-sharing approvals.
Even when data is de-identified, Data Use Agreements (DUAs) are still recommended. They should spell out permitted uses, ban re-identification attempts, and define security controls and redistribution limits. [5][9] In plain English: run de-identified data through the same approval path you already use for vendor access and data-sharing reviews.
Conclusion: A practical checklist for compliant, usable de-identified data
De-identification is a series of deliberate choices, not a one-time task. Start with the use case. Then match the method, data changes, validation, and governance to how the data will actually be used.
Technical controls set the baseline. Governance keeps everything in shape after that. Once direct identifiers are removed, governance helps keep the data usable and aligned with HIPAA. That means documenting methods and approval steps, signing Data Use Agreements, and testing again at regular intervals as the data landscape shifts.
Done well, de-identification helps protect patients, supports HIPAA compliance, and keeps data useful for analytics, research, and operations. Used the same way each time, this checklist helps teams share data more safely without stripping out the parts that still matter.
FAQs
When should I use Safe Harbor instead of Expert Determination?
Use Safe Harbor when you want a plain, rules-based compliance method that’s easy to audit and you can remove all 18 specific HIPAA identifiers.
It’s a good fit when that removal doesn’t cut too much into the data’s usefulness and you have no actual knowledge that the remaining information could identify a person.
What hidden PHI is most often missed during de-identification?
Hidden PHI is easiest to miss in unstructured free text, especially in clinical notes, discharge summaries, and medical reports.
It also slips through in image metadata, such as DICOM headers, text burned into medical images, and file attachments. Another common mistake is stripping out only direct identifiers while missing re-identification risk from quasi-identifiers when those details are combined with outside data.
How often should de-identified data be retested for re-identification risk?
De-identified data shouldn't be treated as a one-time task. It needs regular monitoring and periodic review.
Re-check re-identification risk any time the data changes, the intended recipients change, or the surrounding environment shifts. That also includes cases where new external datasets could make re-identification easier. Periodic reassessments help make sure existing controls still work as risk changes over time.
