When de-identifying healthcare data under HIPAA, organizations can choose between Safe Harbor and Expert Determination. Each method has its own strengths and challenges:
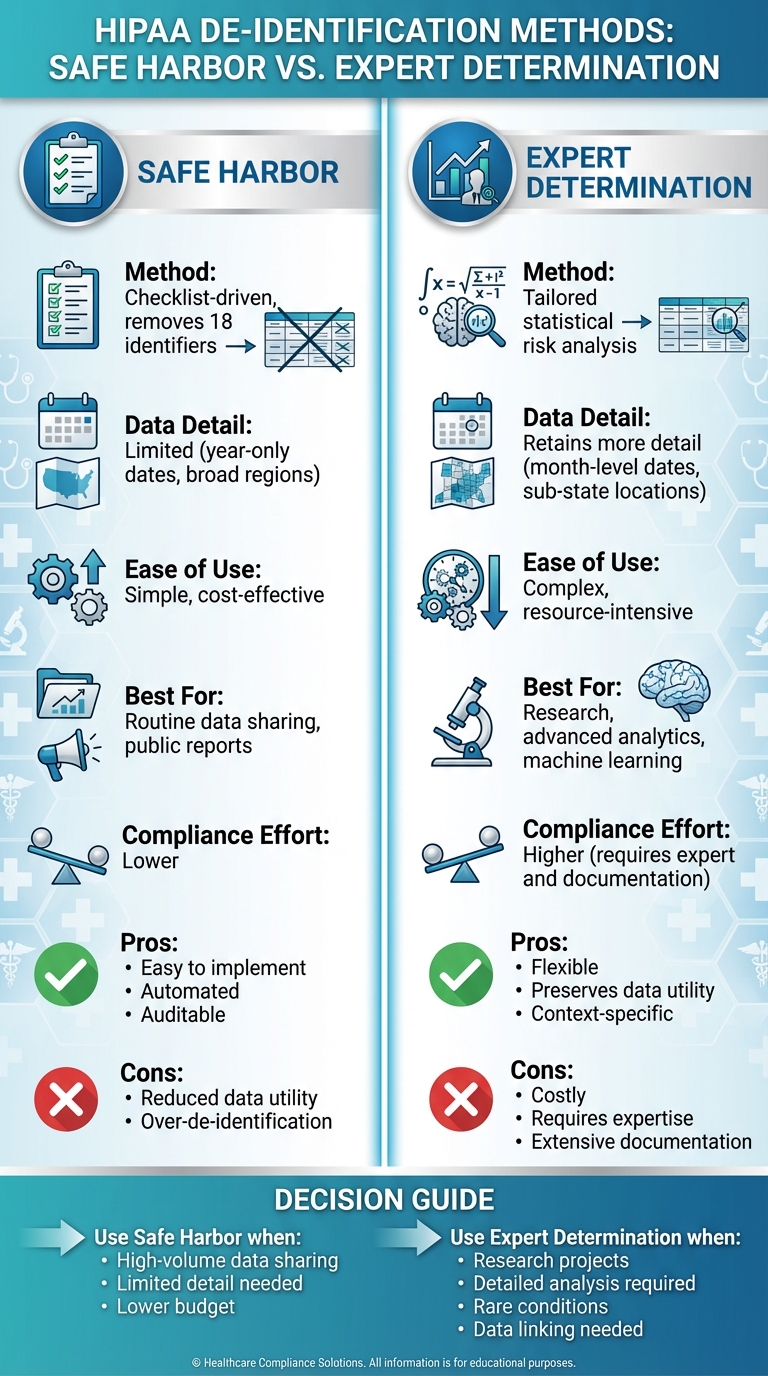
- Safe Harbor: A straightforward, checklist-based approach that requires removing 18 specific identifiers (e.g., names, detailed dates, and addresses). It's simple to implement, cost-effective, and ideal for routine data sharing. However, it limits data utility by generalizing or removing details, which can hinder deeper analysis.
- Expert Determination: A flexible, risk-based method where a qualified expert uses statistical techniques to ensure the re-identification risk is "very small." This method retains more data detail (e.g., month-level dates, sub-state locations) and is better suited for advanced research or machine learning. However, it is more complex, costly, and requires thorough documentation and regular reviews.
Quick Comparison
| Criterion | Safe Harbor | Expert Determination |
|---|---|---|
| Method | Checklist-driven, removes 18 identifiers | Tailored statistical risk analysis |
| Data Detail | Limited (e.g., year-only dates, broad regions) | Retains more detail (e.g., month-level dates) |
| Ease of Use | Simple, cost-effective | Complex, resource-intensive |
| Best For | Routine data sharing, public reports | Research, advanced analytics |
| Compliance Effort | Lower | Higher (requires expert and documentation) |
Bottom Line: Use Safe Harbor for simpler needs like aggregated reporting. Opt for Expert Determination when detailed data is critical for research or analytics. Both methods ensure HIPAA compliance but differ in their balance of simplicity, cost, and data usability.
HIPAA Safe Harbor vs Expert Determination Comparison Chart
HIPAA Safe Harbor Method
How Safe Harbor Works
The Safe Harbor method offers a clear, checklist-driven approach to de-identifying patient data. It requires organizations to remove 18 specific identifiers - like names, Social Security numbers (SSNs), medical record numbers, detailed dates, and street addresses - and ensures that the data cannot reasonably be re-identified when combined with other information [1].
For instance, a hospital preparing aggregated claims for public health reporting might remove patient names, simplify dates to show only the year, and reduce ZIP codes to just the state level. Many organizations streamline this process by using redaction software, which scans for identifiable information and validates the results through dual reviews [1].
Benefits of Safe Harbor
Safe Harbor stands out for its simplicity. The method’s checklist is straightforward, making it easy to train staff and implement. Automation through data pipelines further reduces costs and speeds up the de-identification process, which is especially useful for tasks like quality reporting or building public dashboards [1]. Another advantage is its auditability. Because the rules for removing identifiers are explicit, healthcare organizations can easily document their compliance during HIPAA audits. This transparency makes Safe Harbor a practical choice for high-volume data sharing when fine-grained details aren't essential [1].
Drawbacks of Safe Harbor
However, Safe Harbor has its limitations. Its rigid rules can reduce the usefulness of the data. For example, removing detailed dates makes it impossible to analyze seasonal trends or track precise treatment timelines. Similarly, generalizing geographic data to the state level hampers sub-state epidemiological studies. Another concern is that while Safe Harbor effectively removes the specified 18 identifiers, it doesn’t address quasi-identifiers - combinations like age, gender, and broad location - that could still lead to re-identification, especially for rare conditions. This can result in over-de-identification, which diminishes the data’s value for deeper analysis [1].
Expert Determination Method
How Expert Determination Works
The Expert Determination method relies on statistical analysis to assess the risk of re-identifying individuals in a dataset, rather than following a rigid checklist. A qualified expert evaluates this risk using statistical tools to ensure it remains very small within a specific context [1][2].
The process begins with defining the data elements, intended recipients, and purpose of use. The expert then identifies potential risks by analyzing quasi-identifiers, such as age, gender, or location, which could make the data unique and more identifiable [1][2].
To minimize these risks, the expert applies specific techniques. Generalization involves grouping data into broader categories, like converting an exact age to an age range (e.g., 20–29) or aggregating ZIP codes into larger regions. Suppression eliminates high-risk data points, such as rare medical diagnoses in small populations. Perturbation introduces controlled noise, like slightly altering dates, to obscure exact values while maintaining overall trends. After applying these transformations, the expert validates that the data remains useful for its intended purpose, documents every step of the process, and provides a signed certification confirming that the risk of re-identification is very small [1][2]. This method allows for tailored adjustments that balance data protection with usability.
Benefits of Expert Determination
This approach offers significant flexibility, preserving more detailed data compared to the rigid rules of the Safe Harbor method. For instance, it allows retention of specific details like month-level dates or sub-state geographic information, which are often critical for advanced analyses. Imagine a research team studying the timing of treatments for a rare disease. By using Expert Determination, they can keep precise temporal data while applying statistical safeguards, enabling deeper insights. This adaptability is particularly useful for projects that involve linking data from multiple sources, where overly broad generalizations under Safe Harbor could hinder accurate record matching [1][2][7].
Drawbacks of Expert Determination
While effective, Expert Determination comes with challenges. The process is both costly and complex, requiring the expertise of a qualified professional, which many healthcare organizations may lack in-house. The statistical analysis involved demands significant time and resources [1][2]. Additionally, the method requires thorough documentation, including the expert’s qualifications, threat modeling details, risk thresholds, and records of all transformations and residual risk assessments. If the dataset changes or new external data becomes available, the entire process must be re-evaluated, increasing the administrative burden. Auditing this method is also more intricate compared to the straightforward checklist approach of Safe Harbor [1][2].
Comparing Safe Harbor and Expert Determination
Side-by-Side Comparison
To better understand the differences between these two methods, let’s break down their core characteristics and practical implications. Safe Harbor follows a checklist approach, removing 18 specific identifiers to ensure compliance, while Expert Determination uses statistical techniques to tailor data transformations and reduce the risk of re-identification [1][5].
Each method comes with its own set of trade-offs. Safe Harbor provides straightforward compliance since the HIPAA Privacy Rule explicitly defines which identifiers must be removed, making audits more manageable [5][6]. On the other hand, Expert Determination requires detailed documentation of the expert's qualifications, the risk assessment methodology, and ongoing monitoring. While this adds complexity, it also creates a strong compliance framework when executed properly [1][4].
Another key difference lies in data utility. Safe Harbor’s strict rules - like limiting dates to just the year, grouping ages over 89 into a single "90 or older" category, and restricting ZIP codes to the first three digits (only if the area has more than 20,000 residents) - can significantly reduce the level of detail available for analyses involving time or location [5]. In contrast, Expert Determination allows for more granular data, such as month- or quarter-level dates, detailed age ranges, and finer geographic details, while still meeting HIPAA’s "very small risk" standard through context-specific adjustments. This makes it a better fit for research, machine learning, and advanced analytics [1][3][7].
| Criterion | Safe Harbor | Expert Determination |
|---|---|---|
| Regulatory Basis | Requires removal of 18 identifiers as outlined by HIPAA [5] | Permits de-identification when an expert confirms re-identification risk is "very small" [5] |
| Identifier Handling | Removes fixed identifiers; limits dates to the year; aggregates ages 90+ [5] | Retains granular data (e.g., month-level dates, specific age bands) through tailored adjustments [1][3] |
| Risk Approach | Rules-based with no risk quantification [1] | Quantifies and documents re-identification risk using statistical models [1][7] |
| Data Utility | Lower utility for detailed temporal or spatial analyses [5] | Higher utility for advanced analytics, longitudinal studies, and machine learning [1][7] |
| Compliance Burden | Lower burden with a simple checklist approach [1] | Higher burden due to expert analysis, documentation, and periodic reviews [1] |
| Implementation Cost & Time | Lower cost and quicker to implement; scalable automation possible [2] | Higher initial costs and longer timelines, but justified for projects needing detailed data [2] |
This side-by-side comparison highlights how each method caters to different priorities, whether it’s simplicity and speed or depth and flexibility.
When to Use Each Method
Choosing between Safe Harbor and Expert Determination depends on your project’s data needs and available resources. Safe Harbor works best for cases where broad, high-level data is sufficient. Examples include public datasets for annual reports, hospital quality metrics by year, or benchmarking efforts where year-level dates and regional geography suffice. Organizations looking for a quick, cost-effective, and repeatable process for de-identifying routine datasets will find Safe Harbor a practical choice [1][2].
Expert Determination, however, is the better option when high data utility is essential. For instance, clinical research and outcome studies often require precise date information, such as for analyzing 30-day readmissions or treatment cycles for cancer patients. Similarly, geospatial studies and research on social determinants of health benefit from detailed location data. Machine learning projects, which rely on rich temporal and event sequence data, also align better with Expert Determination. In cases involving rare conditions or small populations, where overly strict data suppression could render the dataset unusable, the tailored approach of Expert Determination justifies its higher cost and governance requirements [1][2][3].
sbb-itb-535baee
Compliance and Documentation Requirements
Both methods comply with HIPAA de-identification standards, but they come with distinct documentation demands for OCR audits and due diligence. Knowing these differences is crucial for staying audit-ready. The documentation practices outlined here lay the groundwork for compliance and play a key role in the decision-making process discussed in the next section.
Safe Harbor Documentation
Safe Harbor's documentation is relatively simple and relies on a checklist approach. Organizations must show they’ve removed all 18 specified identifiers and confirm there’s no actual knowledge that the remaining data could identify an individual [1][2][5].
To meet these requirements, maintain records that include:
- A log of fields removed or generalized.
- Standard operating procedures (SOPs) for using the checklist.
- Processing logs that capture personnel details and timestamps.
Keep it concise - typically, one or two internal forms and system logs should suffice for audit purposes. Finally, include a data steward's signed attestation confirming that no risk of identification remains.
Expert Determination Documentation
Expert Determination involves more extensive documentation since it’s based on customized statistical analysis rather than a fixed checklist [1][2][5]. Compliance hinges on documenting the expert's methods and conclusions in detail.
An Expert Determination report should include:
- The expert's qualifications and a statement of independence.
- A complete inventory of the data reviewed, including fields and their sources.
- A description of the risk assessment methods used (e.g., k-anonymity models or linkage simulations), along with assumptions, thresholds, and transformations like suppression or generalization.
- A quantified residual risk assessment showing a "very small" risk of re-identification.
- Release conditions, such as data use agreements, and a signed attestation from the expert.
This level of detail not only ensures compliance but also helps healthcare organizations maximize data utility while minimizing re-identification risks.
Additionally, Expert Determination documentation must address re-assessment criteria - triggers for reviewing the determination. These could include adding new data fields, changes in data recipients, or new external datasets that might increase linkage risks. It’s also important to track version history, define retention periods, and schedule regular reviews to maintain compliance. This thorough documentation supports ongoing governance and helps organizations choose the most suitable de-identification method for each project.
How to Choose the Right Method
Decision Factors
Selecting the best de-identification method hinges on five key considerations. First, think about the complexity of your data. For simpler datasets, the HIPAA Safe Harbor method might suffice. But if your data includes rare conditions, outliers, or detailed quasi-identifiers, Expert Determination is a better fit. Techniques like k-anonymity can help address these complexities, making Expert Determination more effective for nuanced scenarios.
Your analytical goals also matter. Safe Harbor removes detailed information, such as sub-year dates and sub-state locations, making it suitable for aggregate reports or basic dashboards. On the other hand, Expert Determination retains critical details, which are essential for tasks like rare-event analysis or linking electronic health records with claims data.
Budget and resources are another major factor. Safe Harbor is a cost-effective option, often automated and checklist-driven, requiring minimal expertise. In contrast, Expert Determination demands more resources, including skilled professionals for statistical risk assessments, thorough documentation, and periodic reviews, making it a more resource-intensive approach.
The control mechanisms over data recipients also influence the choice. When sharing de-identified data with trusted recipients under strict agreements - such as prohibiting re-identification, requiring encryption, and mandating audits - Expert Determination's tailored approach to mitigating risks from quasi-identifiers becomes especially useful. Lastly, threat modeling is critical. Assess potential attackers and external datasets that could enable re-identification before finalizing your method.
These factors provide a framework for establishing effective de-identification policies tailored to your specific needs.
Guidance for Healthcare Organizations
Using these decision factors as a foundation, healthcare organizations should develop clear policies outlining when to use each de-identification method. For example, Safe Harbor may work well for broad public data releases with low utility needs, while Expert Determination is better suited for high-utility projects that require detailed data.
Start by conducting data inventories to identify and classify protected health information (PHI). Then, create standard operating procedures for redaction, validation, and approval workflows. Integrating specialized tools, like Censinet RiskOps™, can align de-identification strategies with broader cybersecurity efforts. Censinet RiskOps™ provides a structured approach to managing risks tied to patient data, medical records, and research. As Matt Christensen, Sr. Director GRC at Intermountain Health, explains:
"Healthcare is the most complex industry... You can't just take a tool and apply it to healthcare if it wasn't built specifically for healthcare."
Streamlining resources is crucial. For instance, Terry Grogan, CISO at Tower Health, highlighted the efficiency gains from Censinet RiskOps™:
"Censinet RiskOps™ allowed 3 FTEs to go back to their real jobs! Now we do a lot more risk assessments with only 2 FTEs required."
These improvements make ongoing monitoring and documentation more manageable.
To ensure success, pair your chosen de-identification method with strong governance practices. Regular staff training, diligent vendor oversight, and periodic risk reviews - especially when data elements or external conditions change - are essential. This approach balances data utility, risk management, and resource allocation while maintaining patient safety and meeting regulatory requirements.
Conclusion
Comparing the Two Methods
Safe Harbor and Expert Determination offer two distinct approaches to achieving HIPAA compliance, each with its own set of advantages and limitations. Safe Harbor is a checklist-driven approach, simplifying both implementation and auditing. However, it achieves this simplicity by stripping away granular details, like exact dates and regional identifiers, which can reduce the data's usefulness. While generally effective, this method might leave quasi-identifiers that could potentially allow re-identification in rare cases, such as with uncommon medical conditions or small populations.
On the other hand, Expert Determination takes a more tailored approach. By leveraging statistical risk assessments conducted by qualified professionals, this method ensures a "very small" risk of re-identification while maintaining more of the data's analytical value. It’s particularly suited for research scenarios where retaining details like seasonality or applying advanced techniques - such as generalization or suppression - is crucial. However, this method comes with higher costs, more rigorous governance requirements, detailed documentation needs, and the necessity for periodic reviews as the data environment changes.
Ultimately, these differences underscore the importance of aligning the chosen method with the specific needs and goals of your organization.
Choosing the Best Fit
The decision between Safe Harbor and Expert Determination depends on factors like the complexity of your data, the level of detail required for analysis, budget constraints, and the controls in place for data recipients. Safe Harbor works well for situations where releasing less detailed data is acceptable. In contrast, Expert Determination is ideal for more intricate scenarios that demand retaining higher data utility.
To strengthen de-identification efforts, healthcare organizations should incorporate these methods into broader risk management strategies. Tools like Censinet RiskOps™ can help by offering a structured framework for managing risks across patient data, medical records, and research initiatives. Brian Sterud, CIO at Faith Regional Health, emphasizes the value of such alignment:
"Benchmarking against industry standards helps us advocate for the right resources and ensures we are leading where it matters."
A strong governance framework is equally critical. This includes detailed documentation, regular training, thorough vendor oversight, and consistent risk assessments. Combining robust de-identification practices with effective risk management not only ensures compliance but also safeguards patient data against breaches and other vulnerabilities.
FAQs
What’s the difference between HIPAA Safe Harbor and Expert Determination for de-identifying data?
The primary distinction between these methods lies in how they handle the task of de-identifying protected health information (PHI) under HIPAA guidelines.
Safe Harbor takes a rule-based approach. It requires the removal of 18 specific identifiers, such as names, addresses, and Social Security numbers, from the dataset. Once these elements are stripped away, the data is considered de-identified, provided there’s no reasonable chance it could be re-identified. While this method is clear-cut and easy to follow, it may not suit every dataset, particularly those requiring a more tailored approach.
Expert Determination, on the other hand, is more nuanced. It involves a qualified expert who uses statistical or scientific techniques to evaluate and reduce the likelihood of re-identification. This method is more flexible and works well for complex datasets that don’t fit neatly into the Safe Harbor framework.
Both methods ensure compliance with HIPAA, but they differ in execution. Safe Harbor relies on strict rules, while Expert Determination depends on specialized expertise and a customized analysis.
When is it better to use the Expert Determination method instead of Safe Harbor for de-identifying patient data?
The Expert Determination method works well for healthcare organizations that need a tailored way to de-identify patient data. It's especially helpful for handling complex datasets or situations where preserving the usefulness of the data is just as important as meeting privacy requirements.
Unlike the Safe Harbor method, which sticks to a rigid checklist, Expert Determination involves a qualified expert who evaluates and reduces the risk of re-identification. This makes it a more flexible option, particularly for datasets that don’t align neatly with Safe Harbor’s strict guidelines.
How does the complexity of patient data influence the choice between Safe Harbor and Expert Determination?
The choice between using Safe Harbor or Expert Determination for de-identifying patient data largely depends on the complexity of the dataset. Safe Harbor is ideal for simpler datasets where removing specific identifiers is enough to comply with HIPAA regulations. On the other hand, Expert Determination is better suited for more detailed or nuanced datasets. This method involves a specialized analysis by a qualified expert to ensure the data cannot be traced back to individuals.
For healthcare organizations managing sensitive or highly complex data, Expert Determination provides more tailored solutions, especially when working with unique datasets or advanced applications. Selecting the appropriate method is key to maintaining both regulatory compliance and patient privacy.
