How to Monitor AI Model Performance in Healthcare
Post Summary
Monitoring AI in healthcare is essential to ensure patient safety, maintain trust, and comply with regulations. This is critical as cyberattacks and application downtime represent significant risks to patient care. AI models, especially in critical areas like diagnostics or medical device monitoring, can experience performance drops (silent failures) over time, leading to potential risks like misdiagnoses or unequal treatment. Here's a quick breakdown of how to monitor and manage AI performance effectively:
- Key Metrics: Use sensitivity, specificity, F1-score, AUROC, and calibration scores to evaluate statistical performance. For rare conditions, metrics like AUPRC and MCC are more reliable.
- Clinical Outcomes: Track metrics like readmission rates, mortality rates, and time-to-intervention to measure real-world impact.
- Workflow Monitoring: Assess alert acceptance, override rates, and clinician feedback to ensure tools are practical and trusted.
- Data and Drift Detection: Monitor for changes in input data (covariate shift), outcomes (label shift), or relationships (concept drift) to catch issues early.
- Governance: Assign clear responsibilities, set thresholds for alerts, and establish escalation workflows to address issues promptly.
- Documentation: Maintain detailed logs, audit trails, and dashboards to track performance and ensure compliance with regulations like the Colorado AI Act.
Key Performance Metrics for AI Models in Healthcare
Baseline Model Performance Metrics
When evaluating AI models in healthcare, relying solely on accuracy can be misleading, especially for conditions that are rare. For example, a model predicting "no disease" for every patient could still achieve 95% accuracy if only 5% of patients actually have the condition. This highlights the need for a broader range of metrics to assess performance effectively.
Metrics like sensitivity, specificity, F1-score, MCC (Matthews Correlation Coefficient), AUROC (Area Under the Receiver Operating Characteristic curve), AUPRC (Area Under the Precision-Recall Curve), and the Brier Score each provide unique insights. For instance:
- Sensitivity and specificity focus on identifying true positives and true negatives.
- F1-score and MCC are better suited for rare conditions, where accuracy can fail to provide a complete picture.
- AUROC, while popular, can sometimes overestimate performance in low-prevalence settings due to the abundance of true negatives. In such cases, AUPRC offers a more accurate assessment of performance for the minority class.
Calibration is another critical factor. Even if a model performs well on other metrics, poor calibration - where predicted probabilities don't align with actual outcomes - can erode clinical trust.
A study published in npj Digital Medicine in 2026 compared two FDA-approved mammography AI tools. Interestingly, the model with a lower AUROC (0.882 compared to 0.928) outperformed its counterpart in a key area: it ruled out 29.0% of patients at a 100% safety threshold, compared to just 16.7% for the higher-AUROC model [7].
"The reason [for tentative AI integration] is not merely a lack of accuracy, but a significant gap between an AI's validated statistical performance and the operational safety required for clinical trust." - npj Digital Medicine [7]
These metrics for cybersecurity and performance lay the groundwork for a robust monitoring strategy, helping teams detect and address performance issues before they impact patient care. However, statistical metrics alone aren't enough - clinical outcomes provide a more direct lens into patient impact.
Clinical Outcome Metrics
Statistical metrics evaluate performance in a vacuum, but clinical outcome metrics measure whether an AI model genuinely improves patient care. These include factors like readmission rates, mortality rates, time-to-intervention, and equity gaps across different patient groups.
A great way to track real-world impact is through the Continuous Evaluation Framework (CEF). This framework monitors models over time rather than relying on a single snapshot. Key metrics include:
- Anticipation time: How early the model flags a deteriorating patient.
- Alarming rates: The balance between meaningful alerts and unnecessary noise.
This is especially relevant for tools like sepsis prediction models, which often perform well in controlled testing but generate excessive false alarms in practice. High false-positive rates can lead care teams to ignore alerts entirely, undermining the tool's value [6].
Equity is another crucial factor. Monitoring metrics like worst-group AUC or worst-group false positive rate across demographic groups ensures the model works safely for all patients, not just the majority. Ignoring algorithmic bias can have regulatory consequences, as current guidelines emphasize the importance of addressing disparities in AI systems [4][5].
Tracking these clinical outcomes ensures that AI tools not only perform statistically but also deliver meaningful, equitable benefits in real-world settings.
Workflow and Adoption Metrics
For AI tools to succeed in healthcare, they must earn the trust of clinicians. One of the biggest challenges here is alert fatigue. When high-risk alerts have false-positive rates as high as 80–90%, care teams may start ignoring them altogether [8]. Monitoring alert acceptance rates versus override rates can provide a clear picture of whether the tool is being used as intended.
Stanford Health Care offers a practical example. Their low-value lab test predictor tracks both alert acceptance and override rates, alongside qualitative feedback from clinicians. This helps determine whether the tool reduces unnecessary testing without frustrating staff. Similarly, their inpatient hospice screening tool categorizes clinician responses into actionable categories like "Reach out to team" or "Not relevant." If the "Not relevant" responses exceed a certain threshold, the tool is adjusted or retired [9].
Operational metrics are equally important for AI systems integrated into clinical workflows. Monitoring FHIR write success rates and HL7 ACK rates is essential to catch silent integration failures before they disrupt patient care. A good rule of thumb: if FHIR write success falls below 95% for more than five minutes, it should trigger an automatic alert or kill switch [3]. These operational signals ensure that AI tools function as intended within the broader healthcare ecosystem.
sbb-itb-535baee
How to Set Up AI Model Monitoring Systems
Identifying Data Sources and Update Frequencies
Start by compiling a list of all AI tools in your system. Don’t overlook models quietly embedded in platforms like electronic health record (EHR) systems - they may not be clearly labeled as "AI." Once you’ve identified them, categorize the data sources into three layers: data ingestion (how fresh and accurate your incoming data is), model output (the results the model generates), and clinician interaction (how medical professionals respond to those results).
For high-risk models, establish your clinical ground truth early. Define what outcomes signify correct or incorrect predictions, outline how this data will be collected, and assign responsibility for ensuring its accuracy [1]. Surprisingly, less than 15% of healthcare organizations currently have structured monitoring systems for their AI models [11]. The frequency of updates should match the level of clinical risk. For instance, a sepsis prediction model might need hourly reviews, while a model flagging unnecessary lab tests may only require weekly checks. The closer a model’s output is tied to patient care decisions, the more frequently it should be reviewed [1]. This step ensures that monitoring efforts align with the real-world impact of each model. After building a detailed data inventory, the next focus is on setting clear alert criteria.
Setting Thresholds and Alerts
Once data sources are mapped, the next step is defining alert thresholds. A tiered alert system works well, with informational alerts for emerging trends, warning alerts for signs of drift, and action-required alerts for situations needing immediate intervention or model suspension [11][12]. Instead of relying solely on static thresholds, combine them with trend-based methods to track performance changes over time. For example, a Brier score exceeding 0.20 signals that the model's predictions are straying from actual outcomes, requiring attention [11].
"If no one can answer 'who can disable this CDS within five minutes?' your monitoring program is not mature enough for production clinical use." - Beneficial Cloud [12]
To prevent critical failures, include circuit breakers - automated safeguards that deactivate a model’s recommendations and revert to a safer, rules-based system when thresholds are breached. For fairness monitoring, ensure performance gaps between demographic groups (e.g., Equalized Odds or False Negative Rate Parity) stay below 5% [11]. With thresholds in place, continuously monitor for data shifts that could indicate performance issues.
Detecting Drift and Errors
Drift is a common cause of unexpected performance drops. In healthcare, confirming ground-truth labels, such as a sepsis diagnosis or a 30-day readmission, can take days or even weeks, delaying error detection. To address this, use label-agnostic monitoring pipelines that flag changes in input data distribution before clinical errors emerge [1][13].
Focus on three types of drift: covariate shift (changes in patient demographics or equipment), label shift (variations in outcome frequency), and concept drift (changes in how inputs relate to outcomes due to evolving protocols) [1][2]. Tools like Population Stability Index (PSI) and Maximum Mean Discrepancy (MMD) can help identify these shifts early.
A practical example comes from the GEMINI study, which analyzed data from seven Toronto hospitals between January 2010 and August 2020, covering 143,049 patients. Researchers Vallijah Subasri and Dr. Amol A. Verma used a label-agnostic monitoring pipeline with black-box shift estimators (BBSE) and MMD to track an in-hospital mortality prediction model. During the COVID-19 pandemic, this approach enabled continual learning, improving model performance by a Delta AUROC of 0.44 compared to a static model [13].
Additionally, weak-slice analysis - breaking down performance for specific groups, like older patients or underrepresented ethnicities - is essential. Aggregate metrics may look stable while certain populations face significant declines in model accuracy. Set automated retraining triggers if accuracy stays below a warning threshold for three consecutive days or if drift affects more than 30% of features [11]. Catching these shifts early protects patient outcomes and ensures timely updates to your models.
Governance and Collaboration in AI Monitoring
Cross-Team Ownership of Monitoring
For effective monitoring, it's crucial to assign clear responsibilities. Each AI system in clinical use should have a designated service owner on the IT or engineering side and a clinical safety owner on the care delivery side. A well-defined escalation path connecting these roles ensures that alerts are addressed promptly, rather than ignored [12].
At Duke University Health System, the Algorithm-Based Clinical Decision Support (ABCDS) framework governs 52 active AI models. This framework, built on a "People-Process-Technology" foundation, is managed by a multidisciplinary committee established in 2021. The committee oversees every stage of the AI lifecycle, from procurement to real-world monitoring [16][17].
The approach emphasizes shared responsibility for AI safety, mirroring the practices of Site Reliability Engineering (SRE) teams that manage system uptime. Dashboards tailored for clinical leaders highlight patient safety metrics like sensitivity, specificity, and fairness gaps. Meanwhile, engineering teams focus on metrics such as latency, throughput, and pipeline integrity [12].
"Stewardship means having someone accountable for a model's ongoing behaviour, not just its behaviour at the point of approval." - Dr. Casmir Otubo [15]
This accountability framework lays the groundwork for risk-adjusted monitoring strategies.
Risk-Based Monitoring Strategies
Monitoring efforts should match the clinical risk posed by each AI model. A practical approach is to classify models into two tiers: Limited Governance for low-risk, administrative tools and Full Governance for high-risk tools that directly impact patient safety, clinical outcomes, or resource allocation [17]. High-risk tools - like sepsis alerts, diagnostic aids, or triage models - demand stricter thresholds, frequent reviews, and faster escalation protocols.
To maintain effective AI governance, allocate 10–15% of the AI budget to ongoing monitoring and cyber risk management efforts [17]. Alarmingly, as of 2025, only 23% of health systems had formal AI governance structures, leaving many high-risk models without sufficient oversight [19].
A useful benchmark for action is a performance drop exceeding 5% from baseline. Such declines often necessitate model retraining or deactivation. Automated statistical tests, such as the Kolmogorov-Smirnov test (p < 0.01), can help detect significant shifts in input data distribution, reducing the risk of clinical errors [14].
Escalation and Re-Evaluation Workflows
When alerts are triggered, swift action is essential. Set clear response times - 15, 30, 60, and 90 minutes - for escalating issues [12]. Without these targets, critical alerts might go unresolved, increasing patient risk.
Develop a three-level incident classification system based on clinical severity rather than just technical issues. For instance, a Level 1 incident, such as a model suggesting inappropriate medication, should prompt a report to the Governance Committee within 24 hours [14].
Emergency protocols must empower system owners and clinical safety leads to act immediately. They should have the authority to disable or roll back a model without waiting for committee approval, which could cause dangerous delays in a clinical emergency [12][18]. After any emergency action, a formal after-action review ensures lessons are captured and applied.
Before reactivating a suspended model, three conditions must be met: evidence that the root cause has been resolved, successful shadow monitoring (where the model runs in the background without affecting clinical decisions), and explicit approval from the clinical owner [12]. This controlled reactivation process minimizes the risk of repeated issues and helps rebuild trust in the model’s reliability.
Predictive AI Evaluation and Monitoring
Reporting and Documentation for AI Monitoring
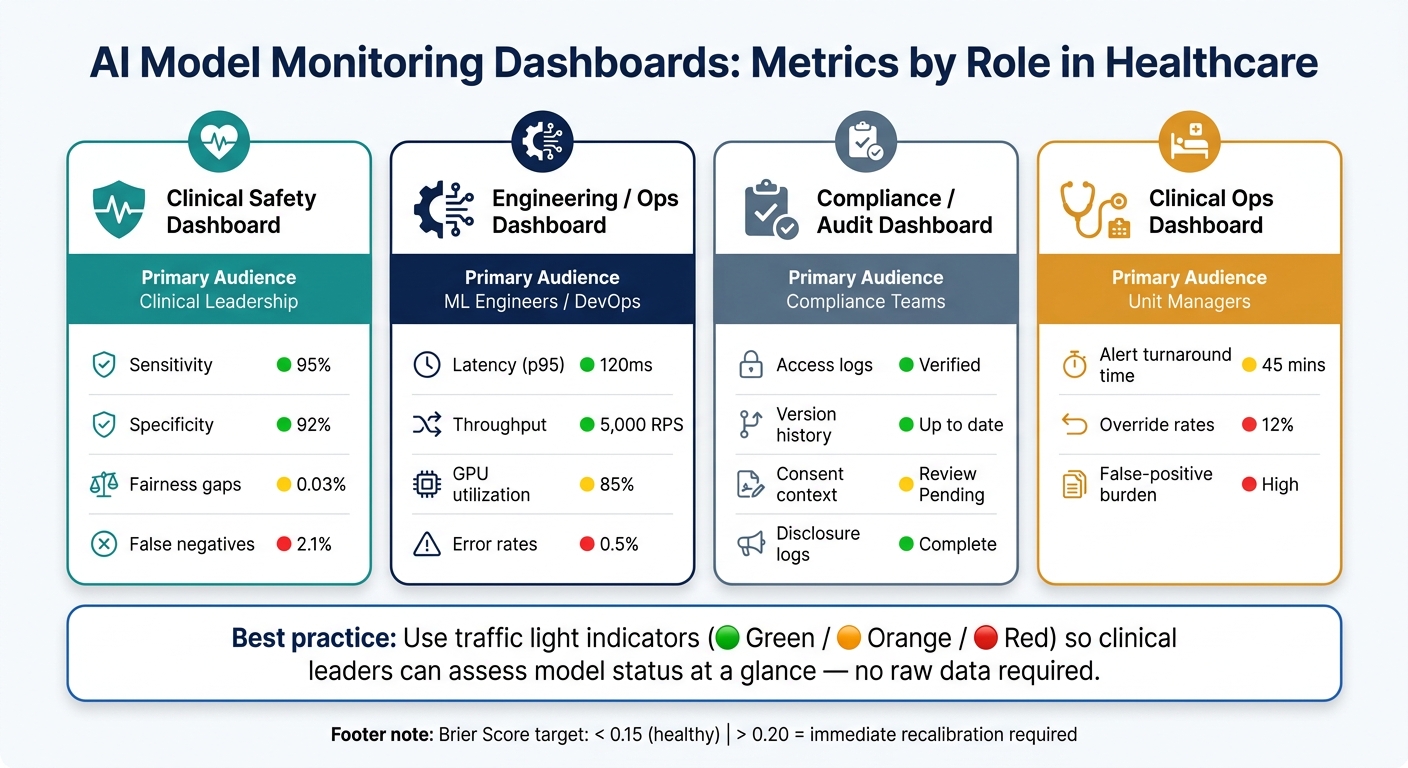
AI Model Monitoring Dashboards: Metrics by Role in Healthcare
Building Effective Monitoring Dashboards
Creating dashboards tailored to specific user roles ensures that monitoring data is both relevant and actionable for each audience. For example, clinical leaders need visibility into patient safety signals - like sensitivity, specificity, and gaps in fairness. On the other hand, engineering teams focus on metrics such as latency, error rates, and the overall health of the AI pipeline. Compliance teams require access to logs and version histories to maintain proper oversight.
"In healthcare AI, the best observability dashboards do not start with infrastructure. They start with clinical risk categories such as missed alert, delayed alert, inappropriate recommendation, and untraceable recommendation." - Daniel Mercer, Senior SEO Content Strategist, Dataviewer.cloud [10]
To make dashboards user-friendly, incorporate traffic light indicators (green, orange, red) to give clinical leaders an at-a-glance view of model performance without requiring them to dive into raw data [11]. For calibration, clinical models should aim for a Brier score below 0.15. Any score over 0.20 signals serious miscalibration that needs immediate attention [11].
| Dashboard Type | Primary Audience | Key Metrics |
|---|---|---|
| Clinical Safety | Clinical Leadership | Sensitivity, specificity, fairness gaps, false negatives |
| Engineering/Ops | ML Engineers/DevOps | Latency (p95), throughput, GPU utilization, error rates |
| Compliance/Audit | Compliance Teams | Access logs, version history, consent context, disclosure logs |
| Clinical Ops | Unit Managers | Alert turnaround time, override rates, false-positive burden |
This structured approach ensures that every audience receives the insights they need, while also laying the groundwork for thorough adverse event documentation.
Adverse Event Reporting and Documentation
When an AI system contributes to a near-miss or adverse event, it’s essential to document the incident immediately. This isn’t just about accountability - it’s an opportunity to learn and improve.
"Medical errors generated by AI could compromise patient safety and lead to misdiagnoses and inappropriate treatment decisions, which can cause injury or death." - Marcus Schabacker, MD, PhD, President and CEO, ECRI [3]
Issues like unexpected PHI in logs, wrong-patient error signals, or cross-context data leaks must be flagged and addressed urgently. These aren’t routine metrics - they require immediate intervention [3].
Thorough and accurate documentation of such incidents not only ensures accountability but also creates a foundation for a strong audit trail.
Maintaining an Audit Trail
After documenting incidents, maintaining a secure and unalterable audit trail is critical for compliance and accountability. Audit records should be immutable, easily searchable, and stored separately from high-volume telemetry. Key details to capture include timestamps, agent versions, patient context IDs, input/output digests, tool call details, and clinical outcomes [3][10]. To protect patient privacy, focus on recording log digests and references rather than raw PHI. Automated regex scans can help identify and address any accidental exposure of sensitive data, such as MRNs, SSNs, or birth dates [3].
In September 2025, the Joint Commission and CHAI released joint guidance that serves as the foundation for voluntary AI certification across over 22,000 accredited organizations [3]. Aligning audit trails with these standards not only boosts compliance efforts but also strengthens patient safety protocols.
Integrating Monitoring Tools and Platforms
Embedding Monitoring in MLOps Pipelines
Integrating monitoring tools into your MLOps pipeline ensures that live operational environments benefit from the same rigor as your documentation and audit trails. This step automates key tasks like performance checks, fairness audits, and drift detection whenever a model or dataset is updated.
Set up automated CI/CD workflows, such as GitHub Actions, to trigger these checks consistently. Use tools like MLflow to log metrics, track model versions, and require SHAP summaries before governance approval. For drift detection and fairness audits, rely on established statistical tests and predefined thresholds to maintain consistency and reliability [20].
"In clinical AI, the stack is not just about training a better model; it is about proving that the model was built correctly, behaves consistently across environments, and can be explained to clinicians, auditors, and regulators." - Tecksite [21]
Centralized Oversight with Censinet RiskOps™
Managing AI model risks individually can leave dangerous gaps. Censinet RiskOps™ offers a centralized solution, functioning like air traffic control for AI governance. It consolidates all AI-related policies, risks, and tasks, streamlining oversight across your organization. Key findings and action items are automatically sent to the right stakeholders, ensuring timely reviews.
The platform's real-time AI risk dashboard provides leadership with a clear, unified view of risk distribution and priority issues. By combining automation - like evidence validation and policy drafting - with human oversight, the system maintains control where it matters most. This is especially crucial in healthcare, where decisions can directly impact patient safety and the protection of sensitive information.
Standardizing Monitoring Across AI Models
As healthcare organizations adopt more AI tools, consistent monitoring becomes essential for scalability and accountability. A three-plane architecture - Data, Model, and Evidence planes - helps manage data quality, model performance, and audit logs effectively [21]. Each component should use immutable artifacts with unique version IDs, ensuring predictions can be reliably reconstructed.
"If your CDS stack cannot reproduce a prediction months later using only stored artifacts, it is not ready for regulated scale." - Tecksite [21]
Validation efforts should go beyond aggregate metrics. Break down performance by subgroups such as age, sex, race, and location, and use time-split cohorts to identify generalization issues before they impact patients. Engage clinical leadership early to establish clear go/no-go criteria, ensuring decisions align with formal risk policies rather than subjective opinions. Incorporating FHIR integration for live clinical data streams further minimizes patient risk and keeps models accountable as your AI portfolio expands [20]. This structured, standardized approach supports scalable and compliant AI oversight in healthcare.
Conclusion: Keeping AI Models Safe and Effective in Healthcare
Keeping a close eye on AI systems is critical in healthcare. Studies reveal that 91% of clinical machine learning models experience performance drops within 1–2 years if not consistently monitored [22]. These models can degrade quietly, producing outputs that seem accurate but could negatively impact patient care.
Dr. Marcus Schabacker highlights the dangers of unchecked AI, warning that errors can lead to serious clinical mistakes [3]. ECRI's findings emphasize the importance of continuous oversight, and updated standards from the Joint Commission and CHAI, introduced in September 2025, now mandate ongoing validation against baseline performance metrics - not just pre-deployment testing [3]. To protect patient safety, healthcare organizations need robust governance frameworks, real-time portfolio risk management, clear accountability across teams, and well-structured escalation processes.
To implement these safeguards, focus on setting clear performance thresholds, tracking protocol-level indicators like FHIR write success and HL7 acknowledgment rates, and keeping PHI exposure monitoring separate from functional metrics. Maintain detailed audit trails and use automated kill switches to alert staff when critical thresholds are crossed. These measures form the backbone of operational standards that prioritize patient safety as AI becomes more integrated into healthcare.
When managed effectively, healthcare AI offers substantial returns: $3.20 for every $1 invested, often within just 14 months [22]. These monitoring and governance strategies not only ensure safety but also help maximize both clinical outcomes and financial benefits. The ultimate goal is to make every AI model dependable, transparent, and trustworthy, enabling broader adoption without compromising care.
FAQs
What’s the fastest way to spot a silent AI failure in a hospital?
The fastest way to spot a silent AI failure is through input monitoring. By keeping an eye on changes in input data - such as shifts in patient demographics, variations in equipment sources, or evolving coding patterns - you can catch early signs of model drift before it starts affecting accuracy.
To strengthen risk management, tools like Censinet RiskOps assist healthcare organizations in identifying and addressing these issues. They also track subgroup performance and human override rates to ensure clinical safety remains intact.
How do we choose the right monitoring metrics for rare conditions?
When evaluating AI performance for rare conditions, it's important to look past accuracy. Why? Because even a high accuracy rate might miss rare, low-frequency cases. Instead, focus on metrics like the F1-score, which balances precision and recall. Another useful metric is the Area Under the Precision-Recall Curve (AUPRC), especially when both false negatives and false positives carry significant weight.
For real-time tracking and automated risk assessments, tools like Censinet RiskOps™ can make the process more efficient and reliable. This ensures you're not just monitoring performance but also maintaining trust in your AI system.
Who should be able to disable an AI model in a clinical emergency?
To prioritize patient safety, healthcare organizations need to establish well-defined decision-making authority for situations where AI models might need to be paused or disabled during emergencies. This responsibility should be clearly documented in a formal governance plan. The plan must specify roles for deployment, reversal, and emergency actions, leaving no room for ambiguity.
Additionally, a thoroughly tested, cross-functional escalation process is essential. This ensures that the team knows exactly who has the authority to disable the system, and they can act within five minutes of an emergency arising.
Related Blog Posts
- AI Model Drift Monitoring: Ensuring Ongoing Performance of Healthcare AI Vendors
- The AI Governance Revolution: Moving Beyond Compliance to True Risk Control
- Governing the Machine: Building an AI Governance Framework That Protects Patients and Enables Innovation
- Beyond the Black Box: Transparency Strategies for Healthcare AI

