How Pseudonymization Meets GDPR Privacy Standards
Post Summary
Pseudonymization is a data protection technique where identifiable information is replaced with pseudonyms, ensuring data cannot directly identify individuals.
It helps organizations meet GDPR requirements by protecting personal data, reducing privacy risks, and enabling secure data processing.
Benefits include enhanced data security, compliance with GDPR, reduced breach risks, and the ability to process data for secondary purposes.
Challenges include managing mapping information securely, ensuring technical safeguards, and balancing data utility with privacy.
Pseudonymization allows data to be re-identified under strict controls, while anonymization permanently removes identifiers, making re-identification impossible.
Examples include using pseudonyms in patient registries for research while protecting privacy and enabling longitudinal studies.
Pseudonymization is a key method for balancing data privacy and usability, especially under GDPR. It involves replacing identifiers in personal data with unique codes, ensuring the data remains useful while reducing re-identification risks. This is particularly important for healthcare organizations handling sensitive information like patient records. Unlike anonymization, pseudonymized data can still be linked back to individuals using securely stored keys or lookup tables, keeping it within GDPR's scope.
Key Takeaways:
- What it is: Pseudonymization replaces direct identifiers (e.g., names) with unique codes but allows re-linking under strict controls.
- Why it matters: Supports GDPR compliance by protecting sensitive data, especially in healthcare, while enabling research and analysis.
- How to implement: Use techniques like tokenization, hashing, or encryption; secure keys separately; and apply robust governance and access controls.
- Ongoing compliance: Regularly audit processes, update safeguards, and train teams to manage risks effectively.
Pseudonymization is a practical tool for managing GDPR requirements, especially for healthcare organizations aiming to protect privacy while maintaining data utility.
GDPR Privacy Principles and Pseudonymization in Healthcare
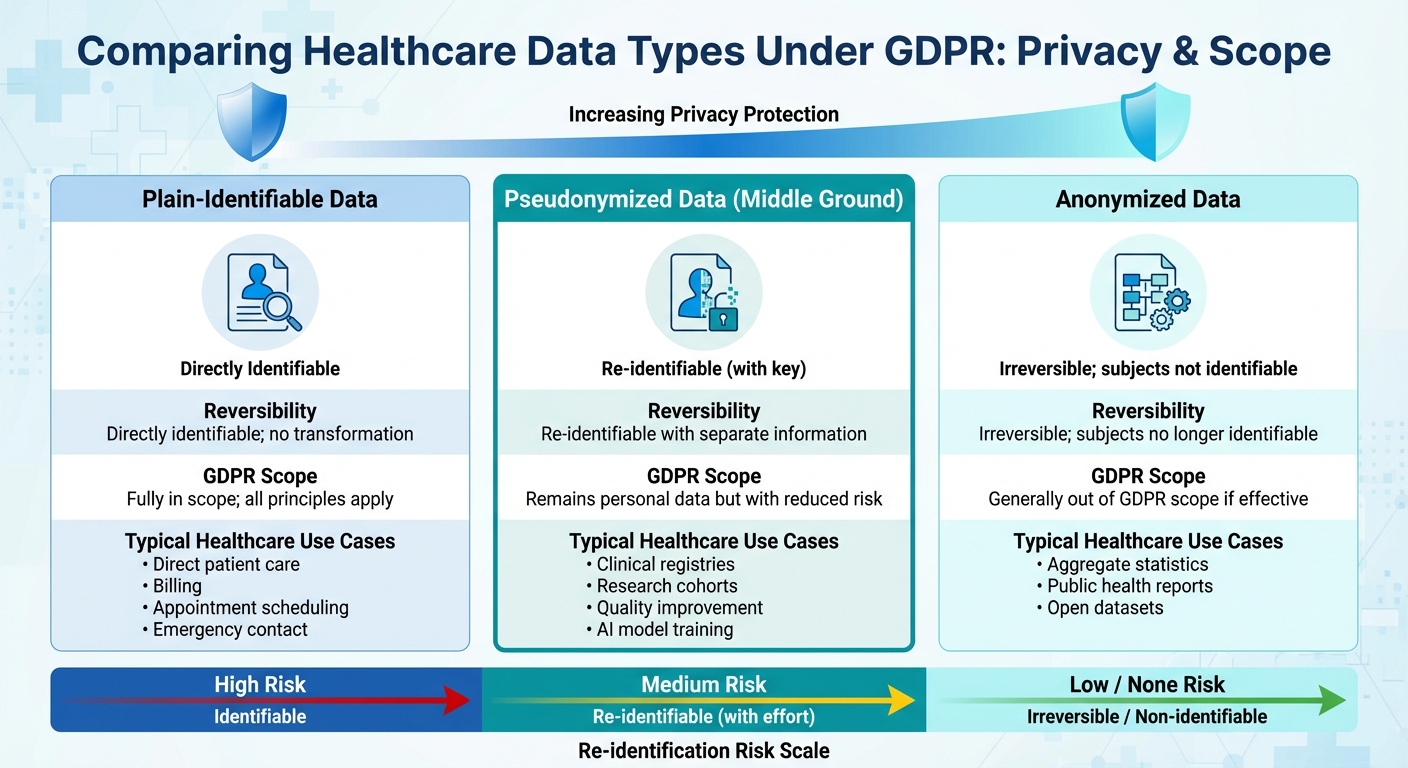
Comparison of Plain-Identifiable, Pseudonymized, and Anonymized Healthcare Data Under GDPR
Understanding GDPR principles is key to building a compliant pseudonymization framework for healthcare data.
Key GDPR Articles and Guidance on Pseudonymization
The GDPR provides a legal framework for pseudonymization. Article 4(5) defines pseudonymization as a process where personal data can no longer be linked to a specific individual without additional information, which must be stored separately and safeguarded through technical and organizational measures [5].
Article 9 emphasizes pseudonymization as a safeguard for special-category data [2]. Article 25 introduces the concept of data protection by design, recommending pseudonymization for systems like electronic health records [4]. Article 32 includes pseudonymization and encryption as essential security measures [1]. Together, these articles outline the technical and organizational requirements necessary for secure pseudonymization.
The European Data Protection Board (EDPB) Guidelines 01/2025 on Pseudonymisation provide further clarity. Effective pseudonymization, according to these guidelines, involves secure key management, strict access controls, and the separate, secure storage of mapping data. The process typically follows three steps: transform the data, store mapping information separately, and restrict access [3]. A practical example highlighted by the EDPB is a dental implant register that uses both temporary and permanent pseudonyms managed by a trusted third party. This approach allows healthcare data to remain useful for longitudinal studies while minimizing privacy risks [4].
How Pseudonymization Supports Core GDPR Principles
Pseudonymization aligns with several core GDPR principles outlined in Article 5. For instance, it supports data minimization by enabling access only to non-direct identifiers. This allows researchers in the U.S. to analyze clinical variables without exposing raw identifiers, with re-linking permitted only under strict controls.
Regarding purpose limitation, pseudonymization allows healthcare data initially collected for care delivery to be repurposed for activities like quality improvement or analytics, while limiting re-identification unless legally justified. In terms of data protection by design and by default, integrating pseudonymization into healthcare systems ensures that data is transformed before being exported to analytics platforms or research repositories. Role-based access controls can ensure that identifiable data is only accessible to users with a legitimate need. Tools like Censinet RiskOps™ help U.S. healthcare organizations assess and document vendor compliance with pseudonymization, encryption, and related safeguards, directly supporting these principles.
Pseudonymization vs. Anonymization vs. Plain-Identifiable Data
Distinguishing between pseudonymization, anonymization, and plain-identifiable data is crucial. Pseudonymized data remains personal data, while anonymized data removes re-identification risks entirely [2].
Achieving effective anonymization in healthcare is particularly challenging due to the richness of clinical details. Rare conditions or combinations of dates and locations can act as quasi-identifiers, making re-identification a risk. Anonymization often requires suppressing or generalizing data, which can reduce its usefulness. Pseudonymization offers a practical alternative, preserving clinical details and longitudinal linkages while lowering re-identification risks. Anonymization, on the other hand, is better suited for cases like public research datasets or fully de-identified registries.
| Data Type | Reversibility | GDPR Scope | Typical Healthcare Use Cases |
|---|---|---|---|
| Plain-identifiable data | Directly identifiable; no transformation | Fully in scope; all principles apply | Direct patient care, billing, appointment scheduling, emergency contact |
| Pseudonymized data | Re-identifiable with separate information | Remains personal data but with reduced risk | Clinical registries, research cohorts, quality improvement, AI model training |
| Anonymized data | Irreversible; subjects no longer identifiable | Generally out of GDPR scope if effective | Aggregate statistics, public health reports, open datasets |
When deciding how to handle data, organizations must consider its intended use. If maintaining a link to the patient is necessary - such as for clinical follow-ups or safety reporting - pseudonymization is usually the better choice. It allows controlled re-identification when needed. However, if data will be widely shared, published, or used in contexts where re-identification poses significant risks, rigorous anonymization is the safer option. This often involves thorough de-identification, aggregation, and legal safeguards to ensure privacy.
Building a GDPR-Compliant Pseudonymization Framework
Now that we've covered GDPR principles, let's dive into how to put them into action. Building a pseudonymization framework that aligns with GDPR standards requires a well-thought-out approach. This includes mapping out your data, establishing clear oversight, and applying the right transformation methods. For healthcare organizations, it starts with understanding your data landscape, setting up governance structures, and choosing the right techniques for handling identifiers.
Analyzing Data Flows and Identifiers
The first step is to catalog every system that processes patient data - this includes both primary systems and supporting applications. For each system, document:
- The types of personal data collected
- Why the data is collected (e.g., direct care, billing, research, or quality improvement)
- Where the data is stored
- How the data moves internally and externally (via interfaces, APIs, file exchanges, or cloud services)
- Which third parties receive the data
Next, focus on identifying the data points that could reveal a patient's identity. These include direct identifiers like names, Social Security numbers, medical record numbers, and contact details. Then, look at quasi-identifiers - details like birth dates, ZIP codes, rare diagnoses, or specific timestamps - that could re-identify someone when combined with other information. Automated tools can help scan both structured data (e.g., databases and HL7/FHIR messages) and unstructured content (e.g., clinical notes, PDFs, or imaging metadata) for these identifiers. Label each data field based on its potential for re-identification and its specific use case.
This detailed data inventory serves as the backbone for governance and helps guide the selection of pseudonymization techniques.
Establishing Governance and Oversight
A strong governance structure is critical. Start by assigning accountability:
- The Data Protection Officer (DPO) oversees GDPR compliance, advises on lawful data processing, reviews pseudonymization strategies, and ensures Data Protection Impact Assessments are completed for high-risk activities.
- The Chief Information Security Officer (CISO) or a similar security leader ensures that technical safeguards - like encryption, access controls, and audit logs - are in place to protect keys and lookup tables.
Technical teams, including data management and engineering, are responsible for implementing pseudonymization pipelines, maintaining accurate data inventories, and enforcing consistent transformation rules. Clinical and research leaders also play a key role in determining how much data detail is necessary for care or studies, balancing privacy with data utility.
Separation of duties is essential. Analysts or researchers working with pseudonymized datasets should not have access to re-identification keys. These keys must be securely stored and accessible only to an authorized group. Clear policies should outline when re-identification is allowed (e.g., for patient care or regulatory needs), who can authorize it, and how such requests are logged and reviewed. Regular audits and governance reviews ensure these policies stay effective.
With governance in place, the next step is to choose pseudonymization techniques suited to your data.
Choosing the Right Pseudonymization Techniques
Different types of healthcare data call for different transformation methods. Here's a breakdown:
- Tokenization: Replaces identifiers like medical record numbers with random or format-preserving tokens. These tokens are stored in a secure key management system, making this method useful for workflows requiring longitudinal data linkage without revealing original identifiers.
- Hashing: Uses a one-way function (often with a secret salt) to ensure the same input always generates the same output. This is helpful for deduplication or linking data across systems. However, hashing must be carefully designed to prevent brute-force or dictionary attacks, especially for low-entropy data.
- Encryption-based pseudonymization: Applies cryptographic algorithms to transform identifiers. Deterministic or format-preserving encryption allows for data joins while keeping encryption keys securely stored. This method supports controlled re-identification and requires strong key management in line with GDPR Article 32.
- Generalization and masking: Reduces data precision to lower re-identification risks. For example, exact dates can be converted to months or years, and parts of an identifier can be masked. This is particularly useful for quasi-identifiers like age, geographic details, or timestamps.
An effective framework combines these methods based on the type of data and its associated risk. For example, use tokenization or encryption for direct identifiers, hashing for selective linkage projects, and generalization for quasi-identifiers. This approach aligns with GDPR's principles of data minimization and purpose limitation.
For U.S. healthcare organizations working with vendors, tools like Censinet RiskOps™ can help assess and document whether third parties are properly implementing pseudonymization, encryption, and other safeguards. This ensures compliance and supports strong governance under GDPR requirements.
Step-by-Step Implementation of Pseudonymization
Once you’ve established a framework, the next step is to implement pseudonymization in live systems. This is where planning transitions into action, requiring close collaboration among IT, security, clinical, and privacy teams. The objective? Transform identifiers while maintaining seamless patient care and operational workflows, all while adhering to GDPR's technical and organizational standards.
Inventory and Classify Health Data
Start by conducting a thorough review of data flows to ensure every system handling patient data is accounted for and each data field is assessed for re-identification risk. This involves scanning systems like EHRs, billing platforms, lab systems, imaging repositories, pharmacy databases, research warehouses, patient portals, and cloud analytics. Automated tools can help identify personal data within structured fields (e.g., database columns, HL7/FHIR messages) and unstructured content (e.g., clinical notes, PDFs, DICOM headers, or identifiers embedded in images).[2][6]
Create a detailed map of data flows for each system. Identify where data is collected, how it’s stored, which internal teams access it, and where it’s shared externally - whether through APIs, file transfers, vendor integrations, or cloud services. Document every third party that receives patient data, noting their role (processor, joint controller, or recipient). This comprehensive view helps uncover hidden copies, backups, logs, and exports that may contain sensitive identifiers.[2][7]
Next, classify each data field based on its re-identification risk:
- Direct identifiers: These include names, Social Security numbers, medical record numbers, complete addresses, phone numbers, email addresses, facial images, and device serial numbers. These fields can directly identify a patient and should be prioritized for pseudonymization when used outside direct care.[8][9]
- Quasi-identifiers: These are fields like dates of service, five-digit ZIP codes, rare diagnoses, occupations, small clinic locations, and timestamps. While not immediately identifying, they can reveal identities when combined with other data. These may require generalization (e.g., converting birth dates to age ranges or ZIP codes to broader regions) or partial masking.[2][9]
Label each field with its classification, intended use, and legal basis under GDPR. This inventory forms the foundation for setting up pseudonymization rules and supports Data Protection Impact Assessments and ongoing governance.[2][7]
Once the inventory is complete, you can move on to configuring pseudonymization rules and managing keys securely.
Configure Pseudonymization Rules and Key Management
Define specific transformation rules for each dataset based on its risk level and purpose. For structured data, methods like tokenization, deterministic cryptography, or generalization may be appropriate. For unstructured data, use precise tools capable of identifying and replacing embedded identifiers.[3][4][5][6]
Key management is critical. Store pseudonymization keys and lookup tables in separate physical and logical systems. Implement strict role-based access control (RBAC) with multi-factor authentication, and log every instance of re-identification.[3][4][5] Establish clear policies outlining when re-identification is allowed - such as for patient safety follow-ups, regulatory audits, or responding to data subject rights requests. Rotate keys regularly, encrypt all key backups, and prepare incident response plans in case of key compromise.[3][5][7]
Integrate Security Controls and Validate Processes
After setting up pseudonymization rules and securing key management, integrate additional security measures to reinforce compliance. Encrypt pseudonymized data both at rest and in transit, and segment networks to isolate sensitive components.[1][5][7] Audit logs are essential - track access to pseudonymized data, attempts to retrieve keys or lookup tables, changes to pseudonymization rules, and all re-identification events. Regularly review these logs as part of your security operations.[1][3]
For U.S.-based healthcare organizations managing third-party data flows, tools like Censinet RiskOps™ can help evaluate whether external partners are implementing proper pseudonymization, encryption, and access controls for PHI and clinical applications. This ensures consistent governance and compliance with GDPR and HIPAA requirements.[1]
Before rolling out pseudonymization in production, test its impact on both data utility and residual risk. Work with clinical and research users to ensure workflows, analytics, and reporting remain functional. Conduct re-identification risk assessments using statistical methods or simulated attacks to confirm that pseudonymization, generalization, and access controls adequately reduce the risk of singling out, linking, or inferring patient identities.[4][5][7]
Document these validation results in your Data Protection Impact Assessment. If residual risks are still too high, refine your pseudonymization rules or add stricter controls, such as broader generalization or tighter access policies. Start with a pilot project - like a quality registry or research dataset - to fine-tune processes before scaling across the organization.[2][4][6]
Involve frontline clinicians and operational leaders during testing to ensure that critical functions like care delivery, safety alerts, and billing remain unaffected. If identifiers are removed from some systems, provide secure, context-based lookups within clinical tools so staff can still access essential information during patient care.[1][2]
sbb-itb-535baee
Ensuring Continued GDPR Compliance and Risk Management
Pseudonymization isn't a one-and-done task; it's a continuous process that must adapt to shifting data flows, emerging threats, and evolving clinical applications. Under GDPR, even pseudonymized health data is still considered personal data, which means organizations must consistently uphold principles like lawfulness, integrity, confidentiality, and accountability. As security threats evolve and cryptographic methods age, it's essential to regularly reassess key lengths, access controls, and pseudonymization techniques, aligning them with current security standards and guidance from bodies like the European Data Protection Board. Below, we’ll explore practical steps to help you evaluate, monitor, and refine your pseudonymization practices under GDPR.
Conducting Data Protection Impact Assessments
Data Protection Impact Assessments (DPIAs) are essential when processing activities pose a high risk to individuals. This includes scenarios like large-scale handling of sensitive health data, systematic monitoring, or advanced applications like AI-based diagnostics and longitudinal patient studies. A DPIA should outline where and how pseudonymization is applied - whether during data extraction from electronic health records, before transferring data to a research database, or at a secure gateway - and detail which identifiers are replaced in the process.
Residual risks, such as re-identification through indirect identifiers or legal provisions allowing data linkage, should be thoroughly assessed. Additionally, organizations must document how pseudonymization integrates with other safeguards, such as encryption, access controls, vendor contracts, and governance measures. For U.S.-based healthcare organizations, tools like Censinet RiskOps™ can help connect DPIA findings with pseudonymization controls and vendor risk assessments, ensuring risks are managed effectively.
Monitoring, Audits, and Incident Response
Effective pseudonymization requires ongoing monitoring, regular audits, and robust incident response plans. Organizations should log and review access to pseudonymization assets, such as keys or lookup tables, and monitor for unusual activity like attempts to export these assets or unexpected behavior from privileged users. Security teams must ensure that data flows align with design specifications, verifying that data sent to research databases or external vendors is consistently pseudonymized and devoid of direct identifiers.
Audits should focus on pseudonymization tool configurations, key management, and the presence of quasi-identifiers that could enable re-identification when combined with other data sources. Risk committees or privacy offices should periodically review DPIA results, incident reports, vendor risk assessments, and updated regulatory guidance, such as the EDPB's 2025 Guidelines on Pseudonymisation. Platforms like Censinet RiskOps™ can centralize these efforts, linking audit findings, vendor risks, and control assessments to specific pseudonymized data flows, ensuring traceability for both regulators and internal stakeholders.
GDPR acknowledges pseudonymization as a valuable measure to reduce risks from breaches, provided it’s implemented effectively and paired with other safeguards. If attackers access only pseudonymized datasets without the corresponding keys or lookup tables (which should be stored separately under strict controls), the risk of direct identification is significantly reduced. To demonstrate compliance during a breach, organizations must maintain detailed documentation of data flows, technical architectures, access controls, logging configurations, and audit outcomes. This level of preparedness, combined with prompt incident response, can help mitigate regulatory penalties, lawsuits, and reputational harm.
Security teams should treat pseudonymization assets as high-value targets, akin to encryption keys or administrator accounts. This means setting up real-time alerts for unusual access to key stores or lookup tables, monitoring for unexpected data exports, and tracking changes to pseudonymization configurations. Incident response plans should include clear steps for handling breaches involving pseudonymization assets. For instance, if a key is compromised, it could escalate a low-risk incident into a notifiable breach due to the potential for mass re-identification. Plans should specify where pseudonymization occurs, which systems manage the keys, and the actions required - such as key rotation, isolating affected systems, and notifying partners or vendors.
Training and Governance for Long-Term Compliance
Sustaining GDPR compliance requires more than just technical measures - it demands a well-informed team and strong governance. Role-specific training is critical for maintaining operational discipline. Clinicians, researchers, IT staff, and legal teams all need tailored guidance on pseudonymization practices, its limitations, and re-identification protocols.
- Clinicians and front-line staff should understand why patient identifiers must not appear in free-text notes or exports intended for research. Instead, they should use pseudonymized identifiers like study-specific codes.
- Researchers and data scientists need to recognize that pseudonymized data is still subject to GDPR and understand the risks of re-identification through data linkage, as well as the approved processes for authorized re-identification.
- IT and security teams must be trained on GDPR and EDPB technical requirements, including secure key management, logging practices, and methods for testing pseudonymization effectiveness.
Privacy and legal teams should focus on how pseudonymization impacts legal bases for processing, DPIA thresholds, cross-border data transfers, and documentation requirements. Vendors and external partners also need onboarding and regular training to understand contractual obligations, secure data handling practices, and the prohibition against re-identification attempts. Tools like Censinet RiskOps™ can support these efforts by managing third-party risk assessments and compliance questionnaires.
Clear policies are essential for defining who can perform re-identification, the purposes for which it’s allowed (e.g., patient safety or legal obligations), and the approval processes involved. Keys should be stored in isolated systems with role-based access controls and multi-factor authentication. Every re-identification event must be logged and periodically reviewed. Comprehensive documentation of pseudonymization decisions, DPIA outcomes, technical measures, and governance structures is crucial for demonstrating compliance to regulators, especially as systems and data flows evolve.
Conclusion
Pseudonymization strikes a practical balance between meeting GDPR requirements and addressing operational needs. By replacing direct identifiers and carefully managing re-identification keys, organizations can minimize the impact of data breaches while enabling secondary data uses within GDPR's safeguards. As noted in Article 32 and Recital 28, pseudonymization is explicitly recognized as a way to reduce risks to individuals and demonstrate the accountability that regulators expect [1][5].
To be effective, pseudonymization must be more than just a technical fix. It requires a combination of strong technical measures - like encryption, tokenization, and securely stored keys - alongside robust organizational practices. These include governance structures, role-based access controls, audit trails, and consistent training for everyone involved, from clinicians and researchers to IT teams and vendors. Tools like Censinet RiskOps™ can support healthcare organizations and their partners by centralizing vendor risk assessments, tracking data flows, and documenting how pseudonymized health information (PHI) is handled. This approach ensures that risks across the supply chain are managed consistently and effectively.
Maintaining compliance in the long term requires aligning daily operations with ongoing risk assessments. Start by mapping your data flows to pinpoint high-risk areas, such as research data repositories, cross-border data transfers, or third-party analytics. For any high-risk activities, use a Data Protection Impact Assessment (DPIA) to validate your strategies. When thoughtfully implemented, pseudonymization not only helps protect sensitive data but also enables safe innovation, data sharing, and reduced regulatory and reputational risks.
Keep in mind that pseudonymization is not a one-and-done solution. As systems evolve, new data sources are integrated, and cryptographic standards change, your framework must keep pace. Regular monitoring, frequent risk evaluations, and ongoing training are essential to ensure your pseudonymization practices stay aligned with GDPR principles and ready to meet the scrutiny of regulators, partners, or patients who want assurance that sensitive health data is protected.
FAQs
What’s the difference between pseudonymization and anonymization under GDPR?
Pseudonymization involves swapping out identifiable details with unique identifiers, often called "pseudonyms." This approach allows the data to be linked back to its original source, but only if combined with separate, securely stored information. It’s a method that aligns with GDPR requirements for controlled data processing while still safeguarding sensitive information.
Anonymization goes a step further by stripping all identifiable elements from the data permanently. Once anonymized, the data cannot be traced back to an individual under any circumstances. For data to meet GDPR standards as anonymized, this process must be absolutely irreversible.
What are the steps to create a GDPR-compliant pseudonymization process?
To align your pseudonymization process with GDPR standards, begin by pinpointing all personal data, with a particular focus on sensitive health information. Categorize this data carefully. Replace any identifiable elements with pseudonyms, and ensure these pseudonyms are stored separately from the original data under strict access controls. For an extra layer of protection, encrypt both the pseudonymized data and the pseudonym keys.
Develop clear protocols for re-identification, restricting it strictly to authorized scenarios. Regularly assess and refine your pseudonymization practices to address emerging risks. Keep thorough documentation and maintain audit trails to showcase compliance. By doing so, your organization can safeguard patient data while adhering to GDPR requirements.
What steps can healthcare organizations take to maintain compliance with GDPR pseudonymization requirements?
Healthcare organizations can stay aligned with GDPR requirements by routinely assessing and refining their pseudonymization methods to keep pace with technological advancements and changing regulations. Regular audits of data processing activities are essential to ensure patient information remains secure and properly protected.
To strengthen compliance efforts, organizations should consider using automated tools that monitor risks in real time. These tools can help detect and address potential vulnerabilities before they become issues. Keeping up with the latest developments in data protection and weaving them into everyday operations is crucial for safeguarding sensitive healthcare data effectively.
Related Blog Posts
Key Points:
What is pseudonymization under GDPR?
Definition: Pseudonymization is a data protection technique defined in Article 4(5) of the GDPR. It involves replacing identifiable information with pseudonyms, ensuring that individuals cannot be directly identified without additional information stored separately. This method allows organizations to process data securely while maintaining the ability to re-identify individuals under strict controls.
Why is pseudonymization important for GDPR compliance?
Importance:
- Pseudonymization aligns with GDPR principles, such as data minimization and security, outlined in Article 5.
- It reduces privacy risks by limiting the exposure of identifiable data during processing.
- Organizations can process pseudonymized data for secondary purposes, such as research, under Article 6(4)(e).
- It demonstrates compliance with GDPR requirements, helping organizations avoid penalties.
What are the key benefits of pseudonymization?
Benefits:
- Enhanced Data Security: Protects personal data from unauthorized access or breaches.
- Regulatory Compliance: Meets GDPR requirements for secure data processing.
- Reduced Breach Risks: Limits the impact of data breaches by separating identifiers from the data.
- Data Utility: Enables organizations to use data for research or analytics while protecting privacy.
What are the challenges of implementing pseudonymization?
Challenges:
- Secure Mapping Management: Mapping information must be stored separately and protected with technical and organizational measures.
- Technical Safeguards: Requires robust encryption, access controls, and decentralized storage.
- Balancing Utility and Privacy: Ensuring data remains useful for analysis while minimizing re-identification risks.
- Compliance Complexity: Organizations must ensure pseudonymization aligns with GDPR requirements and is implemented correctly.
How does pseudonymization differ from anonymization?
Key Differences:
- Pseudonymization: Data can be re-identified under strict controls, making it suitable for scenarios where re-identification is necessary (e.g., research).
- Anonymization: Permanently removes all identifiers, making re-identification impossible. Anonymized data is no longer considered personal data under GDPR.
What are practical applications of pseudonymization in healthcare?
Applications:
- Patient Registries: Pseudonyms are used in registries to enable longitudinal studies while protecting patient privacy.
- Research Data: Allows healthcare organizations to share data for research without exposing identifiable information.
- Data Sharing: Enables secure collaboration between healthcare providers and researchers while minimizing privacy risks.

