Top Frameworks for GDPR Data De-Identification
Post Summary
GDPR data de-identification involves techniques like k-Anonymity, Differential Privacy, and Expert Determination to protect personal data while ensuring compliance with GDPR standards.
k-Anonymity groups records to make individuals indistinguishable within a dataset, reducing re-identification risks. It aligns with GDPR’s requirement to make re-identification "reasonably unlikely".
Differential Privacy adds noise to data to mathematically limit re-identification risks. It offers strong privacy guarantees and aligns with GDPR’s "data protection by design" principle.
Expert Determination uses statistical analysis by qualified experts to assess and minimize re-identification risks, offering flexibility and high data utility.
Challenges include balancing privacy with data utility, addressing linkage attacks, and ensuring compliance with GDPR’s strict anonymization standards.
Organizations should consider their use case, data sensitivity, and compliance needs when selecting between k-Anonymity, Differential Privacy, or Expert Determination.
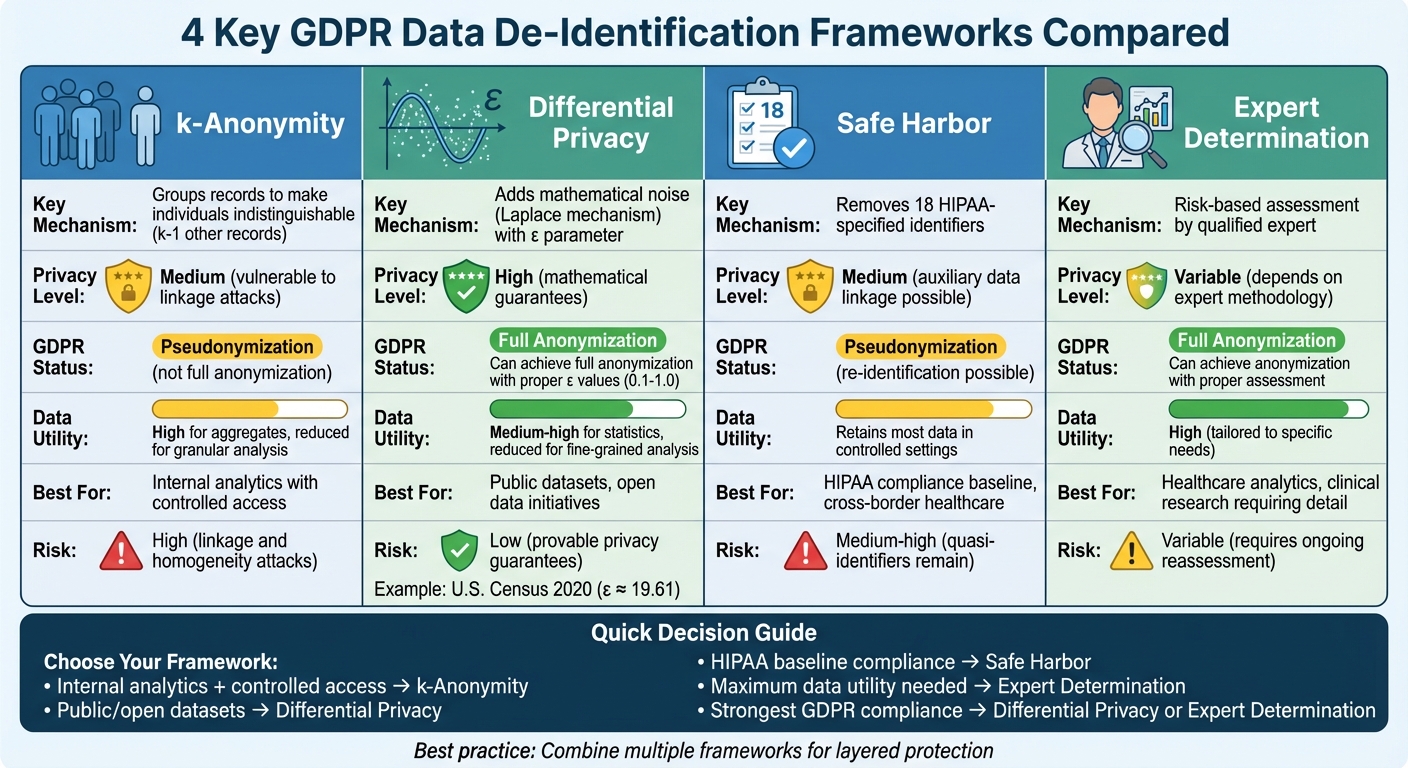
De-identifying data under GDPR is tricky but essential. Whether you're working with healthcare data, analytics, or public datasets, choosing the right method depends on your goals and compliance needs. Here's a quick overview of four key frameworks:
- k-Anonymity: Groups records to make individuals indistinguishable within a dataset. Good for reducing identification risks but vulnerable to linkage and homogeneity attacks.
- Differential Privacy: Adds noise to data to mathematically limit re-identification risks. Strong privacy guarantees but may reduce data precision for detailed analysis.
- Safe Harbor: Removes 18 identifiers (as per HIPAA) but doesn't meet GDPR's stricter anonymization standards. Useful as a baseline but requires additional safeguards.
- Expert Determination: Relies on specialists to assess and minimize re-identification risks. Offers flexibility and high data utility but requires ongoing evaluations.
Each approach has strengths and weaknesses in terms of compliance, privacy, and data usability. Keep reading for a deeper dive into how these methods work and when to use them.
GDPR Data De-Identification Frameworks Comparison: k-Anonymity, Differential Privacy, Safe Harbor, and Expert Determination
1. k-Anonymity
Key Mechanism
k-Anonymity ensures that each record in a dataset is indistinguishable from at least k−1 other records based on quasi-identifiers like age, ZIP code, gender, or admission dates. This is achieved through two primary methods: generalization (replacing specific values with broader categories, like age ranges) and suppression (removing or masking certain data points). By grouping at least k records with identical quasi-identifier values, this method makes it harder to link individual records to external data sources.
A well-known example comes from Sweeney's research, which revealed that 87% of U.S. residents could be uniquely identified using just three pieces of information: a 5-digit ZIP code, gender, and date of birth. In her study, anonymized records were successfully re-identified by matching them with publicly available voter rolls [3]. These techniques form the backbone of k-anonymity and play a crucial role in meeting privacy regulations like GDPR.
GDPR Compliance Strengths
k-Anonymity aligns with GDPR's requirement that re-identification of individuals must be "reasonably unlikely" [3]. It ensures that no record stands out among fewer than k similar entries, making it a reliable method for de-identification. Moreover, it adheres to international standards such as ISO/IEC 27559 and ISO/IEC 20889, which are increasingly referenced by regulators and auditors to evaluate the effectiveness of privacy measures.
In the healthcare sector, k-anonymity supports Data Protection by Design principles and can be incorporated into Data Protection Impact Assessments (DPIAs). For highly sensitive data, organizations can opt for higher k values to further minimize re-identification risks. By using generalization and suppression, they demonstrate a risk-based approach to protecting data. Additionally, integrating k-anonymity into frameworks like Censinet RiskOps™ enhances the monitoring and governance of de-identification practices.
Re-Identification Risk
While k-anonymity reduces certain risks, it does not eliminate all threats. Linkage attacks, where anonymized data is combined with external sources [2], and homogeneity attacks, where groups share uniform sensitive attributes, remain potential vulnerabilities.
Studies on de-identified health records, such as those using datasets like MIMIC-III, have shown that removing direct identifiers alone is insufficient. Advanced methods, like membership inference attacks, can still expose sensitive data [4]. As a result, under GDPR, k-anonymity is often classified as pseudonymization or de-identification rather than a complete anonymization solution.
Utility Preservation
Increasing k values through generalization and suppression can reduce the precision of the data, which may impact the accuracy of predictive models and limit statistical insights [4].
To address this trade-off, organizations can carefully decide which attributes to treat as quasi-identifiers, use local recoding to heavily generalize only high-risk records, and apply hierarchical generalization (e.g., converting ZIP codes to broader regions like counties or states) to retain analytical value. k-Anonymity is often combined with other techniques, such as pseudonymization or differential privacy, to strike a balance between data security and usability. Other privacy frameworks tackle these issues in different ways, depending on the specific use case.
2. Differential Privacy
Key Mechanism
Differential Privacy works by adding carefully calculated noise to query results, ensuring that an individual’s data has minimal impact on the overall outcome. Instead of altering the dataset itself, this method ensures that whether a person’s data is included or excluded, the output remains almost the same. The process relies on the Laplace mechanism, which introduces noise drawn from a Laplace distribution. This noise is scaled based on the ratio of the data sensitivity (Δf) to a critical parameter known as the privacy budget (ε).
The ε parameter plays a pivotal role: lower ε values provide stronger privacy protections by adding more noise, while higher ε values allow for greater accuracy at the cost of reduced privacy. For practical applications, ε values typically range from 0.1 to 1.0, with δ set at 10⁻⁵ to strike a balance between privacy and accuracy. Organizations should document these parameter choices in Data Protection Impact Assessments (DPIAs), as required by GDPR Article 35, to demonstrate their commitment to managing privacy risks. These mechanisms are particularly valuable for meeting GDPR standards by minimizing the risk of re-identification.
GDPR Compliance Strengths
Differential Privacy aligns closely with GDPR Article 25, which emphasizes "data protection by design." It prevents data from being linked back to individuals. Unlike pseudonymization - which is still considered personal data under GDPR - well-executed Differential Privacy can potentially render data anonymous, placing it outside GDPR’s scope if the risk of re-identification is sufficiently low [1][2]. Both the European Data Protection Board (EDPB) and France’s CNIL have endorsed Differential Privacy as an advanced anonymization method, especially for statistical reporting and open data use.
One of its key advantages is its ability to account for worst-case scenarios, assuming adversaries could have access to all other records and extensive background information. This approach aligns with GDPR Recital 26, which requires considering "all means reasonably likely" for re-identification. A prime example of its application is the U.S. Census Bureau, which used Differential Privacy for the 2020 Census, applying a global ε value of approximately 19.61 for person-level tables. This marked the first large-scale use of this technique for national population statistics. Similarly, in healthcare, organizations can incorporate Differential Privacy into frameworks like Censinet RiskOps™ to enhance technical safeguards and support enterprise risk management.
Re-Identification Risk
Differential Privacy is particularly effective at controlling re-identification risks through its ε and δ parameters. However, poor parameter choices - such as a high ε or ignoring cumulative noise effects - can weaken its protective capabilities. Research has shown that inappropriate settings can increase the likelihood of membership inference attacks. By explicitly limiting what can be inferred about any individual, Differential Privacy offers a far more secure solution than traditional de-identification methods, such as those outlined in HIPAA Safe Harbor.
Utility Preservation
Differential Privacy strikes a careful balance between protecting privacy and maintaining data utility. By adding controlled noise, it enables accurate aggregate analyses while safeguarding individual privacy. For large datasets, query errors can be kept within manageable limits - on the order of O(1/√n) - ensuring reliable results [4]. A practical example is Apple’s use of Differential Privacy for emoji suggestions, where noise was added to billions of inputs to prevent inference while maintaining functionality. This demonstrates that privacy and usability can coexist in real-world applications.
The balance between privacy and utility hinges on choosing the right ε value and noise mechanism, whether Laplace, Gaussian, or subsampling. Central Differential Privacy, which relies on a trusted curator, generally provides better utility than local Differential Privacy for the same ε value. To minimize errors, organizations should use established libraries like TensorFlow Privacy, OpenDP, or IBM diffprivlib, rather than attempting to build custom implementations. For instance, in healthcare analytics - such as analyzing patient visit frequencies - the Gaussian mechanism can be applied effectively. Using a sensitivity of Δf = 1, noise is drawn from a normal distribution N(0, σ²), where σ = √(2 ln(1.25/δ))/ε, offering a practical starting point for preserving both privacy and data utility [4].
3. Safe Harbor
Key Mechanism
Safe Harbor, a rule-based approach rooted in HIPAA protocols, builds on concepts like k-Anonymity and Differential Privacy to ensure health data complies with U.S. privacy regulations. Under this framework, 18 specific identifiers defined by HIPAA must be removed to render health data non-identifiable [2].
Organizations typically review their datasets to locate and address direct identifiers. For example, detailed birth dates are replaced with only the year, and ZIP codes are shortened to the first three digits - additional suppression measures are applied for small populations. Free-text fields, which might contain sensitive information, are either removed or processed with redaction tools to eliminate protected health information (PHI) from clinical notes [1][2]. These measures are often automated through ETL pipelines or integrated privacy tools, enabling healthcare organizations to routinely generate Safe Harbor-compliant datasets for purposes like research, analytics, and quality improvement. This de-identification step often serves as a foundation before further GDPR-related risk assessments are applied.
GDPR Compliance Strengths
Although Safe Harbor is a HIPAA-centric framework, it provides valuable insights for organizations navigating GDPR compliance, particularly those operating across the U.S. and EU. By systematically removing direct identifiers, it supports principles like data minimization and privacy by design, ensuring only necessary information is retained for secondary uses [1][2].
For cross-border healthcare collaborations - such as partnerships between U.S. providers and EU research institutions - Safe Harbor de-identification can act as a preliminary measure. This base layer is then bolstered with EU-specific risk assessments [1][3]. Additionally, healthcare organizations can embed Safe Harbor-style de-identification rules into their risk management platforms to evaluate PHI, clinical applications, and medical devices. However, it's important to note that under GDPR, data processed through Safe Harbor is considered pseudonymized rather than fully anonymous, as re-identification remains possible through external data sources [1][2].
Re-Identification Risk
Even after removing the 18 specified identifiers, re-identification risks remain due to the presence of quasi-identifiers, such as diagnosis patterns or rare conditions. These vulnerabilities become more pronounced when data is combined with external sources like public registries, social media, or commercial databases [1][4].
A 2024 study on the MIMIC-III dataset highlighted this issue. Researchers discovered that membership inference attacks could still identify whether a record was part of a training set with higher-than-random accuracy, even after PHI tokens were removed according to de-identification standards [4]. Patients with rare diseases or conditions are particularly at risk, as their records may remain unique and identifiable when cross-referenced with other datasets [2][4]. Therefore, while Safe Harbor reduces the likelihood of identification, it does not meet GDPR's stricter anonymity requirements.
Utility Preservation
The Safe Harbor framework impacts data utility by altering or removing direct identifiers and dates, which can limit certain types of analysis. For instance, truncating dates to the year or ZIP codes to three digits restricts time-series and geographic studies [2].
To address this, organizations often adopt alternative methods to maintain analytical value while safeguarding privacy. For example, full dates might be replaced with relative time measures, such as days since a specific event, or grouped into broader time periods like months or quarters. Similarly, geographic data can be generalized to larger regions, like counties or hospital referral areas, which remain epidemiologically relevant but less granular than ZIP-3 data.
In many cases, Safe Harbor rules are applied only to datasets intended for broad sharing, while more detailed versions are retained in secure, access-controlled environments with additional safeguards such as contractual restrictions and audit logs [1]. These approaches aim to strike a balance between reducing re-identification risks and preserving data utility, aligning with both GDPR and HIPAA expectations for privacy and usability.
sbb-itb-535baee
4. Expert Determination
Key Mechanism
Expert Determination takes a flexible, risk-based approach to de-identification. Instead of following a fixed checklist like Safe Harbor, it relies on a qualified expert to assess whether the risk of re-identification is "very small" using statistical methods [1]. This method allows organizations to adapt de-identification techniques - such as generalization, suppression, perturbation, and aggregation - to the specific needs and characteristics of their datasets [1]. The expert evaluates the data within its context, considering realistic attack scenarios and the potential availability of external data. A formal written report is then produced to document the methods, assumptions, and conclusions regarding any remaining risks. This adaptability is especially useful in areas like healthcare analytics and clinical research, where preserving detailed data is critical for meaningful analysis [1]. It also lays the groundwork for a more nuanced approach to GDPR compliance.
GDPR Compliance Strengths
Expert Determination aligns well with GDPR's principles of "privacy by design" and its risk-based approach to anonymization [1]. When properly executed and documented, it shows that data has been effectively anonymized - or, at a minimum, robustly pseudonymized - with significantly reduced re-identification risks [1]. Its strength lies in systematically assessing whether individuals can no longer be identified through reasonably likely methods, closely matching GDPR's anonymization requirements. Organizations can also follow emerging standards like ISO/IEC 27559:2022 and ISO/IEC 20889:2018 to structure their Expert Determination process. For healthcare organizations handling sensitive patient data, incorporating expert evaluations into their risk management workflows demonstrates compliance with both HIPAA de-identification standards and GDPR-aligned anonymization rules [1].
Re-Identification Risk
Although Expert Determination aims to reduce re-identification risk to a "very small" level [1], it cannot eliminate all risk. The assessment is valid only for the specific threat model and external data environment at the time of evaluation. As new public datasets, commercial databases, or AI-driven linkage techniques emerge, previously safe de-identified data could become vulnerable [4]. However, unlike fixed rule-based methods, Expert Determination evolves to address emerging risks. Organizations should treat it as an ongoing process, revisiting assessments whenever new datasets, additional data sources, or advanced analytic techniques come into play [4].
Utility Preservation
One of the key advantages of Expert Determination is its ability to preserve more data utility compared to rule-based frameworks. Instead of broadly removing identifiers, experts carefully retain detailed information - such as specific age ranges, county-level locations, and precise clinical codes - when the analysis confirms minimal re-identification risk [1]. This precision is particularly valuable in healthcare analytics, clinical research, and AI model development, where maintaining data accuracy is essential for generating useful insights. To maintain data integrity, organizations often pair Expert Determination with strict controls like access restrictions, re-identification prohibitions, and audit logging [1]. This approach strikes a practical balance between maintaining data precision and ensuring privacy.
Framework Comparison: Advantages and Disadvantages
Let's break down the strengths and limitations of each framework, focusing on how they balance privacy protection with data usability.
k-Anonymity works well for generating aggregate statistics but has notable vulnerabilities. For example, if all records in a group share a rare disease and gender, attackers could easily pinpoint an individual. While it maintains high utility for aggregate-level data, it sacrifices detail by generalizing sensitive information into broader categories[1].
On the other hand, Differential Privacy uses a probabilistic method by adding noise to datasets. This ensures that the risk of identifying individuals is mathematically controlled, aligning with GDPR's anonymization requirements through a privacy budget (ε). A practical example is the U.S. Census Bureau, which achieved over 90% accuracy while keeping query errors controlled at ε = 0.1[1].
Safe Harbour follows a straightforward approach by removing 18 specific identifiers, meeting de-identification standards under HIPAA and GDPR. However, its effectiveness diminishes when attackers use auxiliary information. For instance, clinical notes from the MIMIC-III dataset, even after de-identification, were vulnerable to membership inference attacks using models like K-nearest neighbor and random forest[4].
Expert Determination provides flexibility and high data utility by tailoring risk assessments to specific scenarios. However, its effectiveness depends heavily on the chosen methodology and requires ongoing input from specialized experts, which can drive up costs[1][2].
The table below summarizes the key mechanisms, strengths, and trade-offs of each framework:
| Framework | Key Mechanism | GDPR Compliance Strengths | Re-Identification Risk | Utility Preservation |
|---|---|---|---|---|
| k-Anonymity | Groups records into classes | Supports pseudonymization under Recital 26 | High (due to linkage and homogeneity) | High for aggregates; reduced at granular level[1] |
| Differential Privacy | Adds noise (e.g., Laplace mechanism) | Provides provable epsilon-privacy; aligns with Article 25 | Low (mathematical guarantees) | Medium-high for statistics; reduced for fine-grained analysis[1] |
| Safe Harbour | Removes 18 specific identifiers | Complies with de-identification standards | Medium to high (auxiliary data linkage) | Retains most data in controlled settings[2] |
| Expert Determination | Relies on expert risk assessment | Flexible; supports "privacy by design" practices | Variable (depends on expert/method) | High when tailored appropriately[1][2] |
Conclusion
Choosing the right de-identification framework begins with a clear understanding of what you're aiming to protect and how the data will be used. For internal analytics where access is tightly controlled, combining k-anonymity with strong governance policies might be sufficient. However, keep in mind that under GDPR, such data is still considered personal. For public datasets or open data initiatives, differential privacy or Expert Determination becomes a critical requirement.
This decision-making process highlights the complexities healthcare organizations must navigate. As Matt Christensen, Sr. Director GRC at Intermountain Health, aptly states:
"Healthcare is the most complex industry... You can't just take a tool and apply it to healthcare if it wasn't built specifically for healthcare." [5]
When handling patient data, medical devices, or supply chains under both HIPAA and GDPR, many organizations start with Safe Harbour as a baseline and then apply Expert Determination to ensure compliance with GDPR's stricter anonymization standards.
Your regulatory environment plays a major role in shaping de-identification strategies. If you're operating solely under HIPAA, options like Safe Harbour or Expert Determination provide straightforward paths. However, when EU patient data is involved, additional measures such as DPIAs, access logs, and continuous risk monitoring are essential. Tools like Censinet RiskOps™ can help healthcare organizations integrate these assessments into broader risk management processes, ensuring vendors handle PHI responsibly and comply with both HIPAA and GDPR.
It’s important to remember that no single framework guarantees absolute protection [4]. Real-world risks are influenced by factors like adversary sophistication and the availability of external data sources. In practice, a layered approach - combining k-anonymity, differential privacy, and expert determination while carefully documenting trade-offs - offers a more adaptable and resilient strategy for de-identification.
FAQs
What are the key differences between k-Anonymity and Differential Privacy in balancing data privacy and usability?
k-Anonymity ensures privacy by making each record in a dataset indistinguishable from at least k-1 other records. This is typically achieved by generalizing or suppressing certain data points, but these methods can limit how useful the data is for analysis.
Differential Privacy takes a different approach. It adds statistical noise to the data or the results of queries, offering a quantifiable level of privacy while often retaining more of the data's usefulness. However, its success hinges on setting the right parameters - poor choices can compromise privacy.
In short, k-Anonymity focuses on privacy through data uniformity, while Differential Privacy strikes a balance between protecting privacy and maintaining usability by adding controlled noise.
What are the key drawbacks of relying on Safe Harbor for GDPR compliance?
The Safe Harbor framework is no longer a valid option for GDPR compliance. In 2020, the Court of Justice of the European Union ruled it invalid, effectively removing it as a legal basis for transferring personal data from the EU to the United States.
Relying on Safe Harbor today introduces serious compliance risks, as it fails to meet GDPR's strict standards for safeguarding personal data during cross-border transfers. Organizations must turn to stronger, more current mechanisms to align with GDPR requirements and ensure data protection.
When is it best to use Expert Determination for GDPR-compliant data de-identification?
Expert Determination works best when data de-identification needs a tailored approach, particularly with complex datasets. This method depends on the expertise of a qualified professional who evaluates and reduces the risk of re-identification. It's a go-to option for cases where standard methods might fall short.
Many organizations choose Expert Determination for handling sensitive or complicated data. It offers the adaptability and accuracy needed to meet GDPR standards while safeguarding privacy.
Related Blog Posts
Key Points:
What is GDPR data de-identification?
Definition: GDPR data de-identification involves techniques that remove or obscure personal identifiers to protect individual privacy while enabling data use. Common methods include k-Anonymity, Differential Privacy, and Expert Determination, each offering varying levels of privacy and data utility.
What is k-Anonymity, and how does it support GDPR compliance?
- Definition: k-Anonymity ensures that each record in a dataset is indistinguishable from at least k-1 other records based on quasi-identifiers like age, gender, or ZIP code.
- GDPR Compliance: It aligns with GDPR’s requirement to make re-identification "reasonably unlikely" by grouping records and reducing uniqueness.
- Limitations: Vulnerable to linkage and homogeneity attacks, which can compromise privacy.
What is Differential Privacy, and why is it effective for GDPR?
- Definition: Differential Privacy adds noise to data or query results, ensuring that individual contributions to a dataset cannot be inferred.
- GDPR Compliance: It aligns with GDPR’s "data protection by design" principle by mathematically limiting re-identification risks.
- Strengths: Provides strong privacy guarantees and is effective for statistical reporting and analytics.
- Limitations: May reduce data precision, impacting detailed analyses.
What is Expert Determination under GDPR?
- Definition: Expert Determination involves statistical or scientific analysis by qualified experts to assess and minimize re-identification risks.
- GDPR Compliance: Offers flexibility and high data utility, making it suitable for complex use cases like AI and research.
- Challenges: Requires ongoing evaluations, expert involvement, and detailed documentation.
What are the challenges of GDPR data de-identification?
Challenges:
- Balancing privacy with data utility, as stricter privacy measures often reduce data usability.
- Addressing risks like linkage attacks, where anonymized data is combined with external datasets.
- Ensuring compliance with GDPR’s strict anonymization standards, which require that re-identification is "reasonably unlikely".
How can organizations choose the right de-identification framework?
Considerations:
- k-Anonymity: Best for straightforward compliance and low-risk datasets.
- Differential Privacy: Ideal for statistical reporting and analytics requiring strong privacy guarantees.
- Expert Determination: Suitable for high-value datasets where retaining data utility is critical.

